Using Azure OpenAI Service for processing claim calls
Table of Contents
Introduction #
In this post, we’ll quickly look into how we can use Azure OpenAI Service to automatically process claim calls. For example, let’s assume we have the following call, which we transcribed from the phone conversation using Azure Speech API:
Caller: Hi, I just had a car accident and wanted to report it.
Agent: OK, I hope you're alright, what happened?
Caller: I was driving on the I-18 and I hit another car.
Agent: Are you OK?
Caller: Yeah, I'm just a little shaken up.
Agent: That's understandable. Can you give me your full name?
Caller: Sure, it's Sarah Standl.
Agent: Do you know what caused the accident?
Caller: I think I might have hit a pothole.
Agent: OK, where did the accident take place?
Caller: On the I-18 freeway.
Agent: Agent: Was anyone else injured?
Caller: I don't think so. But I'm not sure.
Agent: OK, well we'll need to do an investigation. Can you give me the other drivers information?
Caller: Sure, his name is John Radley.
Agent: And your insurance number.
Caller: OK. Give me a minute. OK, it's 546452.
Agent: OK, what type of damages has the car?
Caller: Headlights are broken and the airbags went off.
Agent: Are you going to be able to drive it?
Caller: I don't know. I'm going to have to have it towed.
Agent: Well, we'll need to get it inspected. I'll go ahead and start the claim and we'll get everything sorted out.
Caller: Thank you.
From this call, let’s try to extract data points like call reason, accident location, involved persons, insurance numbers, damages and a short summary. If we can do this, this would allow to automatically ingest the details into the CRM. Typically, this is often done manually by agents - however, if we can automate it we can save the agent multiple minutes of work per call.
Information extraction with Azure OpenAI Service #
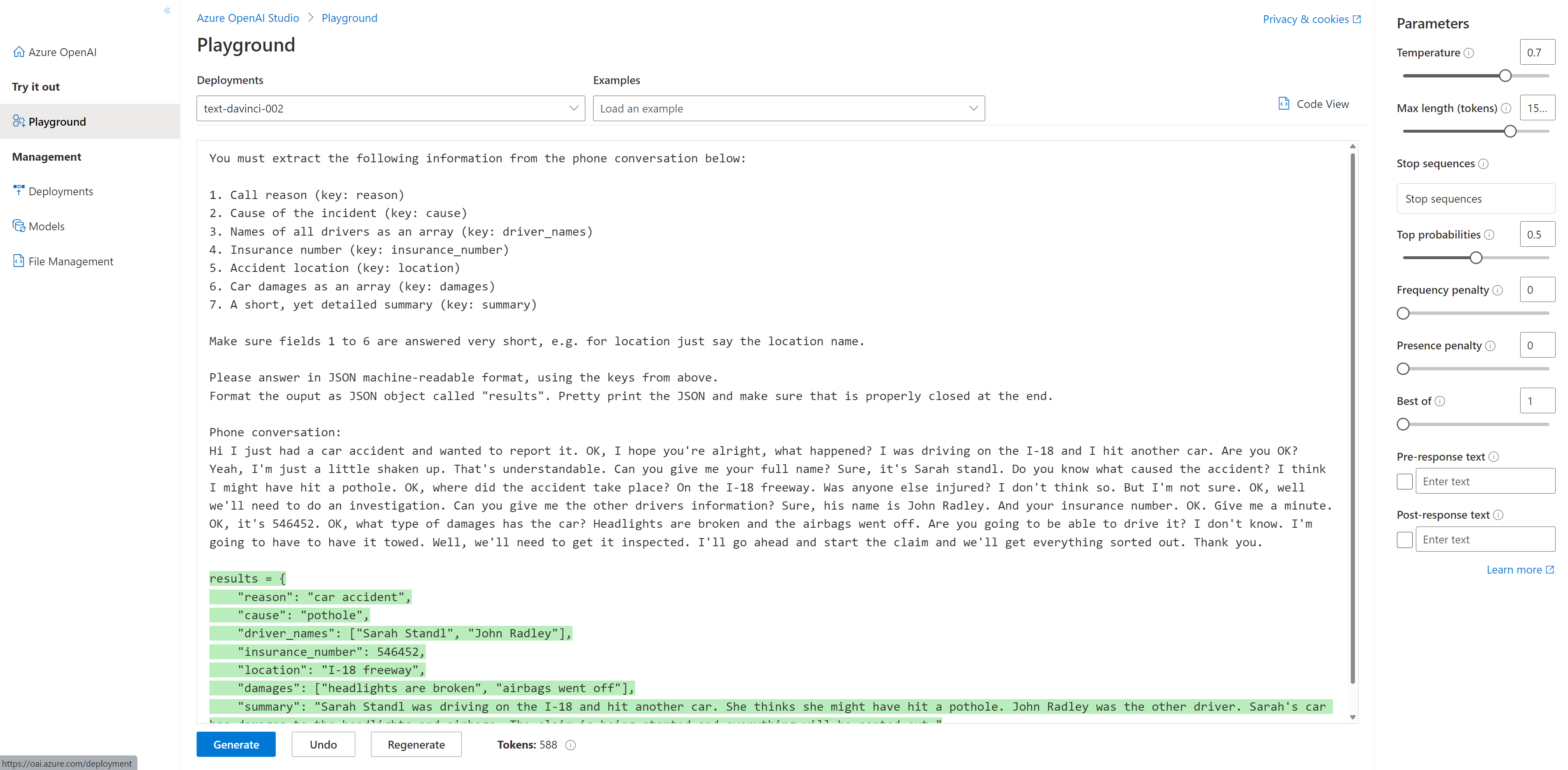
To extract all the data points, we’ll be using OpenAI’s most powerful GPT-3 model text-davinci-002 with a temperature of 0.7. We’ll give it a generous 1500 tokens (the query typically uses under 1000 tokens). For the prompt, we’ll use a zero-shot training approach by very precisely specifying what we want GPT-3 to extract:
You must extract the following information from the phone conversation below:
1. Call reason (key: reason)
2. Cause of the incident (key: cause)
3. Names of all drivers as an array (key: driver_names)
4. Insurance number (key: insurance_number)
5. Accident location (key: location)
6. Car damages as an array (key: damages)
7. A short, yet detailed summary (key: summary)
Make sure fields 1 to 6 are answered very short, e.g. for location just say the location name.
Please answer in JSON machine-readable format, using the keys from above.
Pretty print the JSON and make sure that is properly closed at the end.
Phone conversation:
Hi I just had a car accident and wanted to report it. OK, I hope you're alright, what happened? I was driving on the I-18 and I hit another car. Are you OK? Yeah, I'm just a little shaken up. That's understandable. Can you give me your full name? Sure, it's Sarah standl. Do you know what caused the accident? I think I might have hit a pothole. OK, where did the accident take place? On the I-18 freeway. Was anyone else injured? I don't think so. But I'm not sure. OK, well we'll need to do an investigation. Can you give me the other drivers information? Sure, his name is John Radley. And your insurance number. OK. Give me a minute. OK, it's 546452. OK, what type of damages has the car? Headlights are broken and the airbags went off. Are you going to be able to drive it? I don't know. I'm going to have to have it towed. Well, we'll need to get it inspected. I'll go ahead and start the claim and we'll get everything sorted out. Thank you.
Once we send the example, we will receive the following completion:
{
"reason": "To report a car accident",
"cause": "Hitting a pothole",
"driver_names": [
"Sarah Standl",
"John Radley"
],
"insurance_number": 546452,
"location": "I-18 freeway",
"damages": [
"Headlights are broken",
"Airbags went off"
],
"summary": "Sarah Standl was driving on the I-18 when she hit a pothole and caused damage to her car. She exchanged insurance information with the other driver, John Radley."
}
This looks pretty good and is easily suitable for some further downstream consumption. But let’s discuss a bit, why this actually works.
Prompt Explanation #
Firstly, it is important to tell GPT-3, what we expect it to do:
You must extract the following information from the phone conversation below:
<more details on what to extract>
Phone conversation:
<payload>
Instructing it to “extract information” from the “phone conversation” below helps the model to understand what it is asked to do and where it can actually find the payload on which it should operate. It is important to state where the phone conversation starts by writing “Phone conversation:”.
Next, we specify what GPT-3 needs to extract:
...
1. Call reason (key: reason)
2. Cause of the incident (key: cause)
3. Names of all drivers as an array (key: driver_names)
4. Insurance number (key: insurance_number)
5. Accident location (key: location)
6. Car damages as an array (key: damages)
7. A short, yet detailed summary (key: summary)
...
This section is pretty straight forward, but it is important to note that since we want a machine-readable JSON as an output, it helps to specify where we expect an array and what keys we want it to use.
Lastly, we give it even more precise information on what to do:
...
Make sure fields 1 to 6 are answered very short, e.g. for location just say the location name.
Please answer in JSON machine-readable format, using the keys from above.
Pretty print the JSON and make sure that is properly closed at the end.
...
Telling the model to be concise with the answer helps to shorten the responses and avoids that GPT-3 extracts longer chains of words for its answers. For extracting JSON, it helps to not only say that we want JSON, but also to tell it that it should use the “keys from above” and that the JSON should be properly closed. Otherwise, GPT-3 tends to sometimes forget to close the JSON document.
Next Steps #
While this works well, it might not automatically generalize well across all kinds of call center transcripts, especially for more complex ones. Therefore, two things should be considered before deploying this to production:
- A good validation strategy
- Using fine-tuning to further enhance extraction accuracy
Validation strategy #
For validating some of the extracted key-value pairs (e.g., person names, insurance number, etc.), historic data can be used to easily validate the output of the prompt. In this case, a simple string matching approach can be applied to calculate accuracy.
However, for more open-ended key-value pairs (e.g., the summary) it is more challenging to automatically “judge” how accurate the field is. In this case, it might make sense to calculate the results for maybe a few hundred calls and then have them reviewed by humans. Surely, this is cost and labor-intensive, but allows for a good validation regarding if a human derives value from the summary.
Fine-tuning #
One other option is to fine-tune the model. This also requires historic data, so that the prompt and the expected completion form a training dataset. From this, text-davinci-002 is fine-tuned. This helps to further improve the quality of extraction, but also helps to avoid hallucination and other challenges that GPT-3 might introduce. Surely, this is more effort but will ultimately result in a, likely, more robust model.
Summary #
This post showed how we can use Azure OpenAI Service to extract machine-readable information from unstructured call center transcripts. We used a zero-shot learning approach, that can easily extract a variety of data points and even generate a short summary of what happened in the call. This can be used to e.g., automatically populate the CRM after a call, open a ticket, file a claim, etc. For productionizing the prompt, we also discussed how this model can be evaluated and further improved by fine-tuning it.