Understanding Azure OpenAI's x-ratelimit-remaining-tokens and x-ratelimit-remaining-requests headers
Table of Contents
Introduction #
Azure OpenAI has (silently) introduced two new headers for token and request tracking (x-ratelimit-remaining-tokens and x-ratelimit-remaining-requests), which help to get a feeling of how many requests and tokens an API caller is still allowed to perform. This post explains how we can interpret them, as they are not as straight forward to understand as one might think or hope.
New Headers #
The two new headers we’ll discuss here are returned for each API call (at least for the models that support the headers) and are the following:
x-ratelimit-remaining-tokens- Returns how many tokens the caller can still consume without getting a429backx-ratelimit-remaining-requests- Returns how many inference requests the caller can still perform without getting a429back
So let’s do a quick example:
Model deployment:
- Model: gpt-4-turbo-2024-04-09
- Configured token quota: 20k TPM (Tokens/min)
- Request quota: 120 RPM (Req/min) - Azure OpenAI gives 6 RPM per 1k TPM
- Dynamic quota: Disabled
So let’s run a quick test with:
- Prompt tokens: 100
max_tokens: 25
Once the API request comes back, the usage is reported correctly (same results as when counting it beforehand using tiktoken):
"usage":{
"completion_tokens": 25,
"prompt_tokens": 100,
"total_tokens": 125
}
and if we look at our headers, we see the following:
x-ratelimit-remaining-tokens: 19913x-ratelimit-remaining-requests: 19
Tokens look kind of right (even though it should be 19875), but why is the request limit only 19? Shouldn’t we have 119 left? Let’s dive into it!
Deep dive into x-ratelimit-remaining-tokens #
To figure out how tokens are measured, let’s run a more sophisticated test with the following properties:
Model deployment:
- Model: gpt-35-turbo-1106
- Configured token quota: 10k TPM
- Request quota: 60 RPM
- Dynamic quota: Disabled
Call properties:
- 100 Input tokens
- 2000 max_tokens (the generation will stop well before, but we need to “eat” up token quota to hit the limit)
In this case, we calculate the actual token cost that was deducted from our quota by subtracting it from our known quota (10k) or the last reported remaining tokens from the API response. This means we run single-threaded, no calls in parallel, and wait until each call is done. Let’s run it for a bit over a minute:
Time 0.0s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining tokens: 7939 / Tokens used: 100+73=173 / Actual token cost: 2061
Time 1.9s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining tokens: 5878 / Tokens used: 100+74=174 / Actual token cost: 2061
Time 3.6s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining tokens: 3815 / Tokens used: 100+71=171 / Actual token cost: 2063
Time 5.4s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining tokens: 1753 / Tokens used: 100+74=174 / Actual token cost: 2062
Time 7.8s / Model gpt-35-turbo-1106 / HTTP 429
...many more 429 errors...
Time 59.6s / Model gpt-35-turbo-1106 / HTTP 429
Time 60.2s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining tokens: 1752 / Tokens used: 100+74=174 / Actual token cost: 1
Time 62.2s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining tokens: 1752 / Tokens used: 100+73=173 / Actual token cost: 0
Time 64.5s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining tokens: 1752 / Tokens used: 100+74=174 / Actual token cost: 0
Time 66.7s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining tokens: 1753 / Tokens used: 100+67=167 / Actual token cost: -1
Time 68.6s / Model gpt-35-turbo-1106 / HTTP 429
...many more 429 errors...
Firstly, we can see that we can get four initial calls through, which was expected. Each call requires 100+2000=2100 tokens in total and we need to stay below 10k tokens per minute. Furthermore we see the remaining tokens decrease until we have less available than our requested payload cost. We also clearly see that the high max_token settings removes valuable tokens from our quota, despite the response only being ~75 tokens (as shared in earlier posts, always keep max_tokens as low as possible).
In addition, we see that tokens start to get “refilled” exactly 60 seconds after they were consumed. They do not get refilled at once, but rather on a rolling basis (otherwise the first call after the 60 second mark would have had a cost of ~-8400). This means Azure OpenAI uses a rolling window of 60 seconds to manage the TPM quota. As an example, if we right now place a call that uses 5000 tokens, we’d get back 5000 tokens of quota 60 seconds later. This aligns with the documentation (Understanding rate limits), where it is stated that the quota management happens on 10 or 60 seconds windows (depends on the model). This approach makes sense, as it allows for large API calls to pass through.
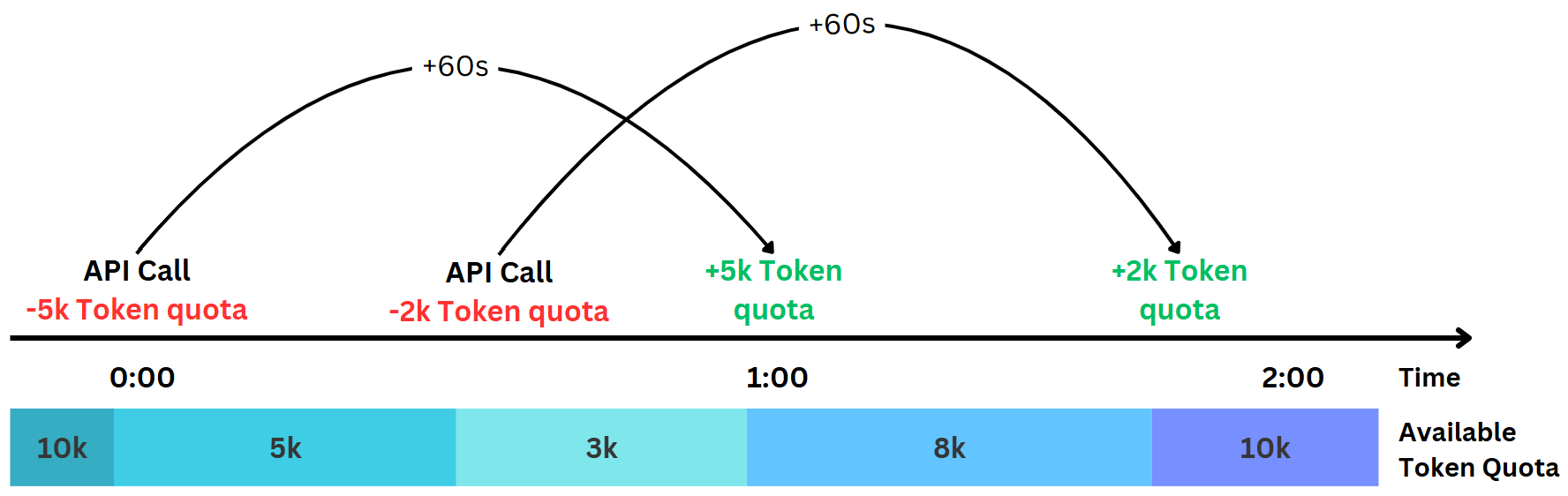
However, it is unclear to me why the actual token cost is ~2061 and not 2100 and I could not figure out why this is happening. However, it always seems to be below the actual used token amount.
Deep dive into x-ratelimit-remaining-requests #
Let’s repeat the same test to understand how the remaining requests header works, but let’s reduce the TPM so we can test the behavior with fewer API calls:
Model deployment:
- Model: gpt-35-turbo-1106
- Configured token quota: 2k TPM
- Request quota: 12 RPM
- Dynamic quota: Disabled
Call properties:
- 100 Input tokens
- 10 max_tokens (to not hit any TPM quota limit)
Time 0.0s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining requests: 1 / Remaining tokens: 1838
Time 2.1s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining requests: 0 / Remaining tokens: 1674
Time 3.9s / Model gpt-35-turbo-1106 / HTTP 429
...more 429 errors...
Time 10.0s / Model gpt-35-turbo-1106 / HTTP 429
Time 10.6s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining requests: 0 / Remaining tokens: 1511
Time 12.6s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining requests: 0 / Remaining tokens: 1349
Time 14.3s / Model gpt-35-turbo-1106 / HTTP 429
...more 429 errors...
Time 20.5s / Model gpt-35-turbo-1106 / HTTP 429
Time 21.1s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining requests: 0 / Remaining tokens: 1187
Time 22.9s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining requests: 0 / Remaining tokens: 1024
Time 26.4s / Model gpt-35-turbo-1106 / HTTP 429
...more 429 errors...
Time 30.7s / Model gpt-35-turbo-1106 / HTTP 429
Time 31.4s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining requests: 0 / Remaining tokens: 861
Time 33.1s / Model gpt-35-turbo-1106 / HTTP 200 / Remaining requests: 0 / Remaining tokens: 699
Time 34.8s / Model gpt-35-turbo-1106 / HTTP 429
...more 429 errors...
This looks very different from what we were expecting after the first test! Only two calls pass through - how can this be? Well, if we look at the full log, it becomes clear: the RPM limit is not enforced on a minute window, but rather on a 10 second window. This means, if we made a call right now, we’d get back a +1 “call refill” 10 seconds later. This also explains why we only get 1/6th of the full minute quota that the UI and documentation shows us. Initially, this caused a lot of confusion for me personally (“Why can’t I push more more calls through!!!”), but made sense once I understood how it works.
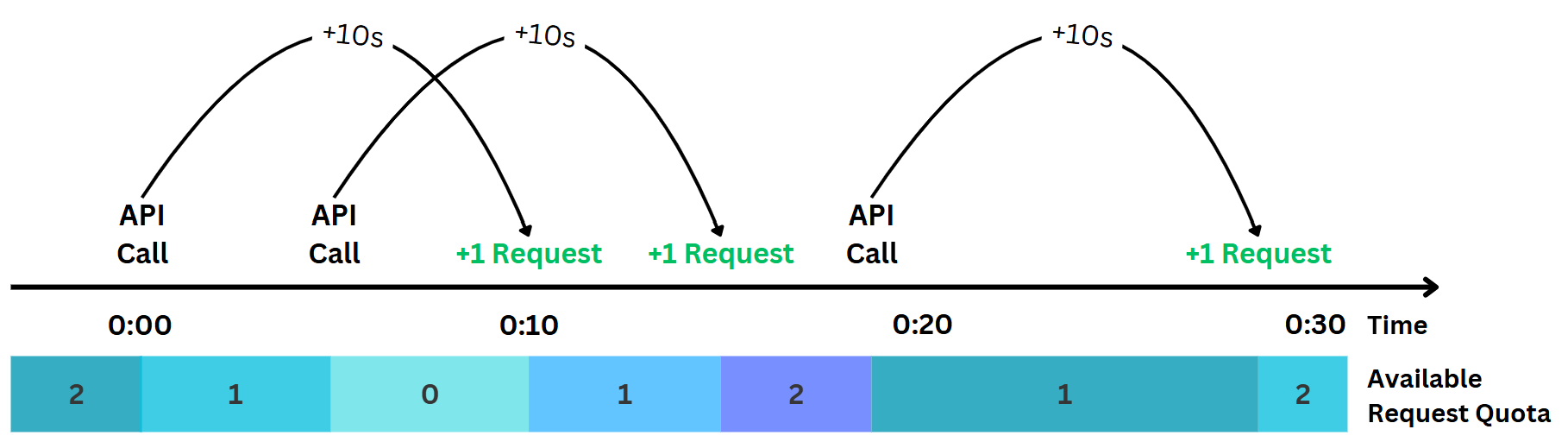
Summary #
Using the x-ratelimit-remaining-tokens and x-ratelimit-remaining-requests headers in Azure OpenAI can be a useful tool to estimate how many calls we can still make before e.g., needing to switch to a different model deployment or resource. However, it is crucial to understand on which time-window those metrics operate and how they get “refilled”. Hence, in summary:
- Token quota gets refilled 60 seconds after a call has been accepted (by the amount of tokens deducted)
- Request quota gets refilled 10 seconds after a call has been accepted
With this, it is easy to optimize throughput or run batch jobs more efficiently.