Sharing Azure OpenAI Provisioned Throughput (PTU) for multiple use cases with Azure API Management
Table of Contents
Introduction #
This post explains how multiple use cases can safely co-exist on Azure OpenAI’s Provisioned Throughput (PTU) offering so that we can:
- Get higher utilization of the Provisioned Throughput resource (instead of having to buy one PTU per use case)
- Track token consumption per use case
- Ensure use cases don’t step on each others’ toes
- Prioritize certain use cases by
- Limiting their throughput
- Limiting their access to PTUs during certain times of the day or days of the week
And obviously, our goal is to make this work for both streaming and non-streaming chat completion calls.
This post is a continuation of my previous post Smart Load-Balancing for Azure OpenAI with Azure API Management and builds upon the discussion there.
Typical scenarios #
So when planning to run multiple use cases on one PTU deployment, our main motivation is typically to save cost. At the same time, we need to make sure that the benefits of the PTU (low latency responses, high throughput) are not lost due to use cases aggressively “eating up” the whole throughput capacity (noisy neighbors).
Hence, when sharing one PTU deployment across multiple use cases we should differentiate between two scenarios:
- All use cases have the same priority
- Some use cases have lower priority than others (therefore could potentially become noisy neighbors)
For example, if we have two customer-facing chatbots or copilots, we want the same, quick, real-time response behavior for both of them. Both use cases have likely the same priority and therefore could run on the same PTU. In case we run out of throughput capacity, we’d surely need scale up, or in case we’re underutilized, we could add more similar use cases or scale down. Easy!
However, let’s say we have one batch use case that processes a lot of documents and one customer-facing chatbot. The batch processing workload could easily eat up the whole PTU throughput capacity during main business hours, which would obviously defeat most of the value prop of the PTU. Hence, we need to be a bit more careful in this scenario.
So what we’ll do now is to discuss those two scenarios as they pose different architectural challenges.
Scenario 1 - Multiple use cases with the same priority #
This scenario assumes that all use cases sharing the PTU have similar priority. In most cases, this means all use cases have the same quick, real-time response requirements, such as e.g., end-user facing chatbots or copilots and therefore want to use the PTU for low-latency responses. Azure OpenAI PAYGO resources should only be used to economically handle occasional peaks.
One way to address this scenario is through the following architecture:
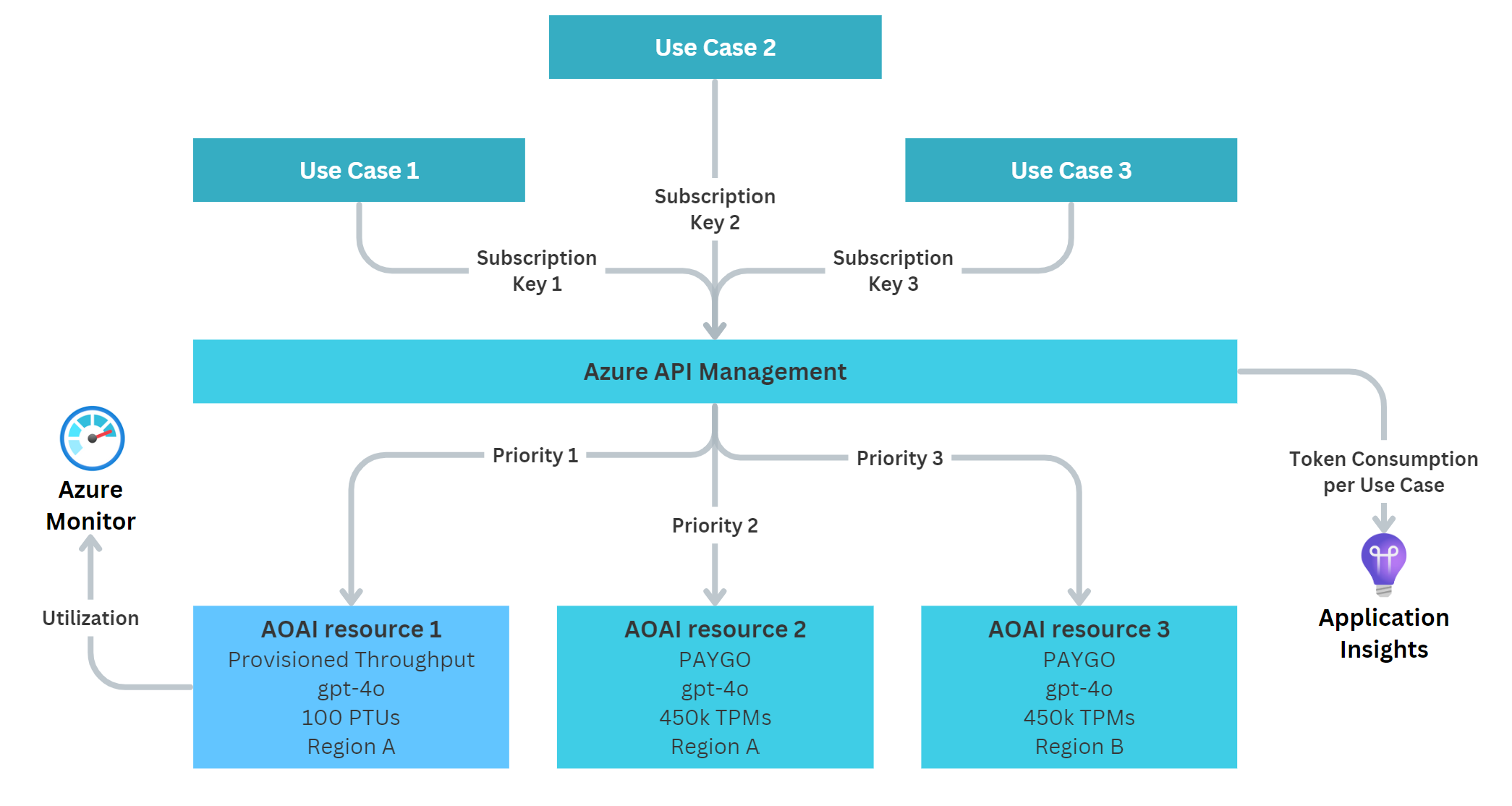
We use a single instance of API Management (APIM) with a single API endpoint. All use cases connect to that one endpoint using their own APIM subscription keys. We do this so we can later track tokens per subscription key, and therefore per use case. This can be useful for showback or chargeback within the organization. To achieve this technically, APIM is configured to emit token metrics per use case to Application Insights, where they are stored for later analysis. With a simple Log Analytics query, we can then get the consumed tokens per subscription key for any desired time frame.
Behind APIM, we leverage multiple Azure OpenAI resources. In our example we configure:
- An AOAI resource that hosts our PTU (priority 1) - This means all traffic should go to the PTU first, as long as there are no
429errors. This makes sure that as many requests as possible are processed by the PTU, which enables fast responses and drives up utilization, hence saves money. - An AOAI resource with PAYGO (priority 2) - This is a PAYGO deployment within the same region as the PTU, but in a separate AOAI resource. This allows us to have all model deployments be called the same, e.g.
gpt-4o. In case the PTU is out of throughput, we can fall back to this PAYGO instance first. Surely, this means slower response times, but gives us a safety net and also allows us to deal with occasional peaks for which the PTU might not be economically feasible. - An AOAI resource with PAYGO (priority 3) - This is another PAYGO deployment, but within a different region as the prior two resources. This is to cover the case that our PTU and the PAYGO resource (either only our resource or the whole data center) are at capacity. This is our double safety net and ideally, this resource should never get called.
Lastly, we track the PTU utilization in Azure Monitor. This allows us to see if we still have good headroom or if it is potentially time to scale up our PTU deployment (i.e., buy more capacity). At the same time, this also gives us an indicator if we have too many PTUs deployed and could potentially scale down or deploy more use cases on them.
Scenario 2 - Multiple use cases with different priorities #
In this scenario we assume that our use cases have different latency requirements:
- Some might require fast responses (often customer-facing)
- Some use cases maybe might not care too much (but won’t complain if they are fast too), and
- Some purely would use PTU to save money (e.g., batch workloads)
Here, the core idea is to utilize the PTU as much as possible (save cost) but without creating a noisy neighbor problem. This could easily arise if a large batch workload is starting to send many API requests to the PTU, thus using up all its capacity. A latency sensitive use case then might need to revert back to PAYGO, thus suffering from slower response times. This scenario is hard to solve, as we typically do not know when the low-priority workload is starting (surely, in same cases we are in control of it).
Solution 1 - Two PTU deployments #
As said, solving this scenario perfectly is not easy. However, we can make some tradeoffs and get to a reasonably good solution using this simple architecture:
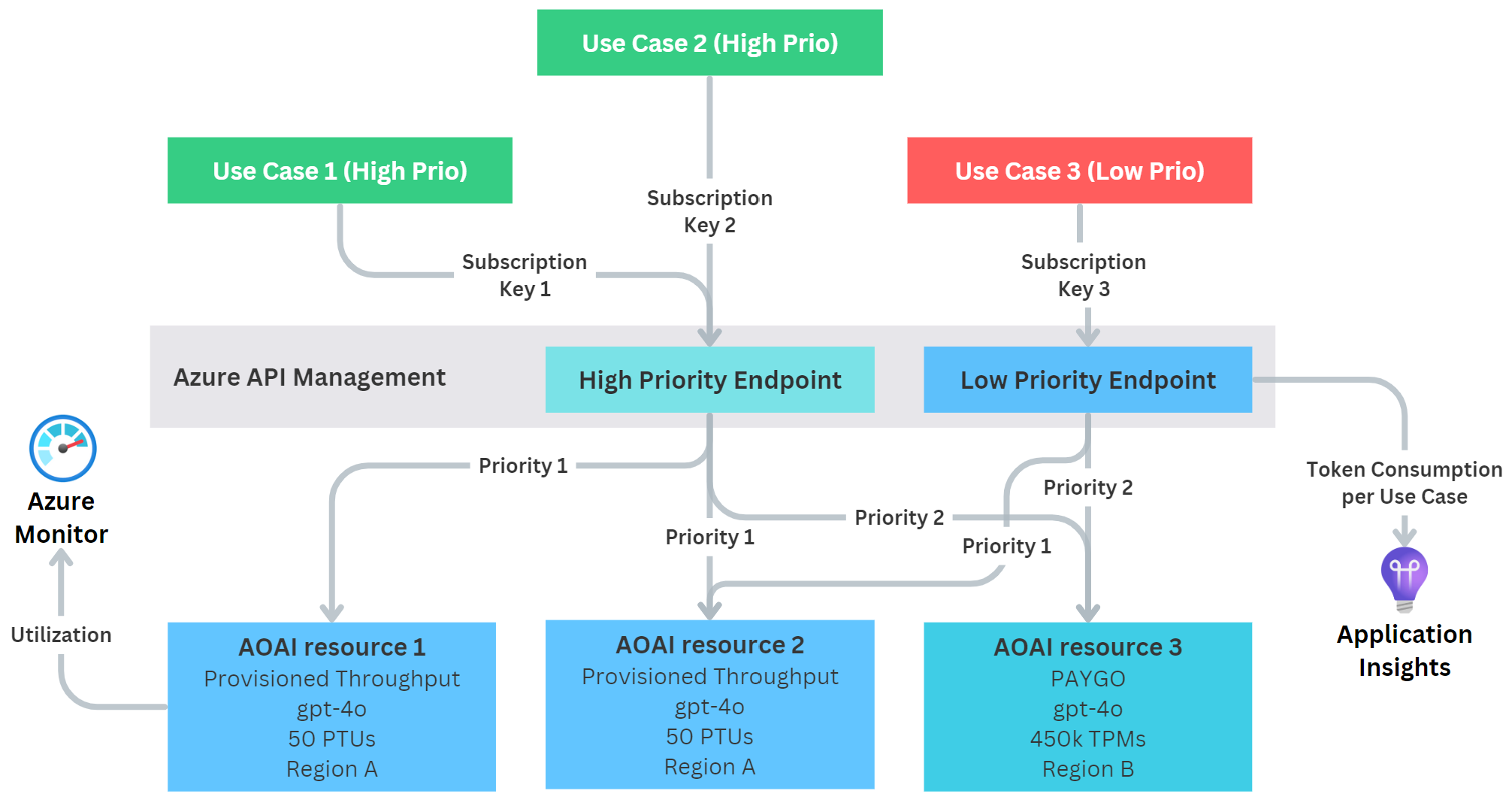
Again, we use a single APIM instance but we deploy two API endpoints:
- One endpoint for high-priority workloads
- One endpoint for low-priority workloads
(Alternatively we could also use one single endpoint that routes based on the APIM subscription keys, but this requires a bit more coding and configuration!)
Same as before, all use cases connect to their respective endpoints using their own APIM subscription key. Within APIM, we can limit API access for the low-priority use case to just be allowed to access the low-priority endpoint.
Now the main idea here is that instead of using one shared PTU resource, we split it up into two AOAI resources, each holding half of the PTUs. This obviously requires twice the capacity, so for very small workloads this might not be economically feasible. However, with models becoming cheaper and faster, it is more feasible than ever. Now to architect this, we define the following access pattern:
- Our high-priority endpoint gets access both PTUs
- Our low-priority endpoint gets access only one PTU
This effectively means that:
- Our high-priority workloads can leverage up to 100% of the overall PTU capacity, but are guaranteed at least 50%
- Our low-priority workloads can leverage up to 50% of the overall PTU capacity
Obviously, these percentage numbers can be tweaked, as long as each PTU has the minimum amounts of PTUs required for a given model.
Behind APIM, we configure the following Azure OpenAI resources:
High-priority endpoint
- An AOAI resource that hosts the first PTU (priority 1)
- An AOAI resource that hosts the second PTU (priority 1) - This should be in the same region, but requires an additional AOAI resource, so that both PTU resources can name their model deployments the same (e.g.,
gpt-4o) - An AOAI resource with PAYGO (priority 2) - For fallback to PAYGO within the same region
Low-priority endpoint
- Points to the AOAI resource that hosts the second PTU (priority 1)
- Points to the AOAI resource with PAYGO (priority 2)
Both endpoints should also have a secondary PAYGO resource in a different region as a secondary fall back (as discussed earlier), but for sake of simplicity this is not shown here.
Yes, this architecture is by no means perfect (requires at least 2 PTU deployments to get started), but it is easy and quick to implement, and yet flexible enough to handle growth over time.
Solution 2 - Using a time-based approach #
Often enough, our use cases show different usage patterns during the course of a day. For example, a chatbot might get used heavily from 8am to 10pm, but does not receive much traffic during the night. At the same time, batch workloads might be happy to primarily run at night, especially when they are not time-critical. We can leverage these day/night patterns to our advantage and limit access to PTUs based on time.
To safely enable this scenario, we can deploy the following architecture:
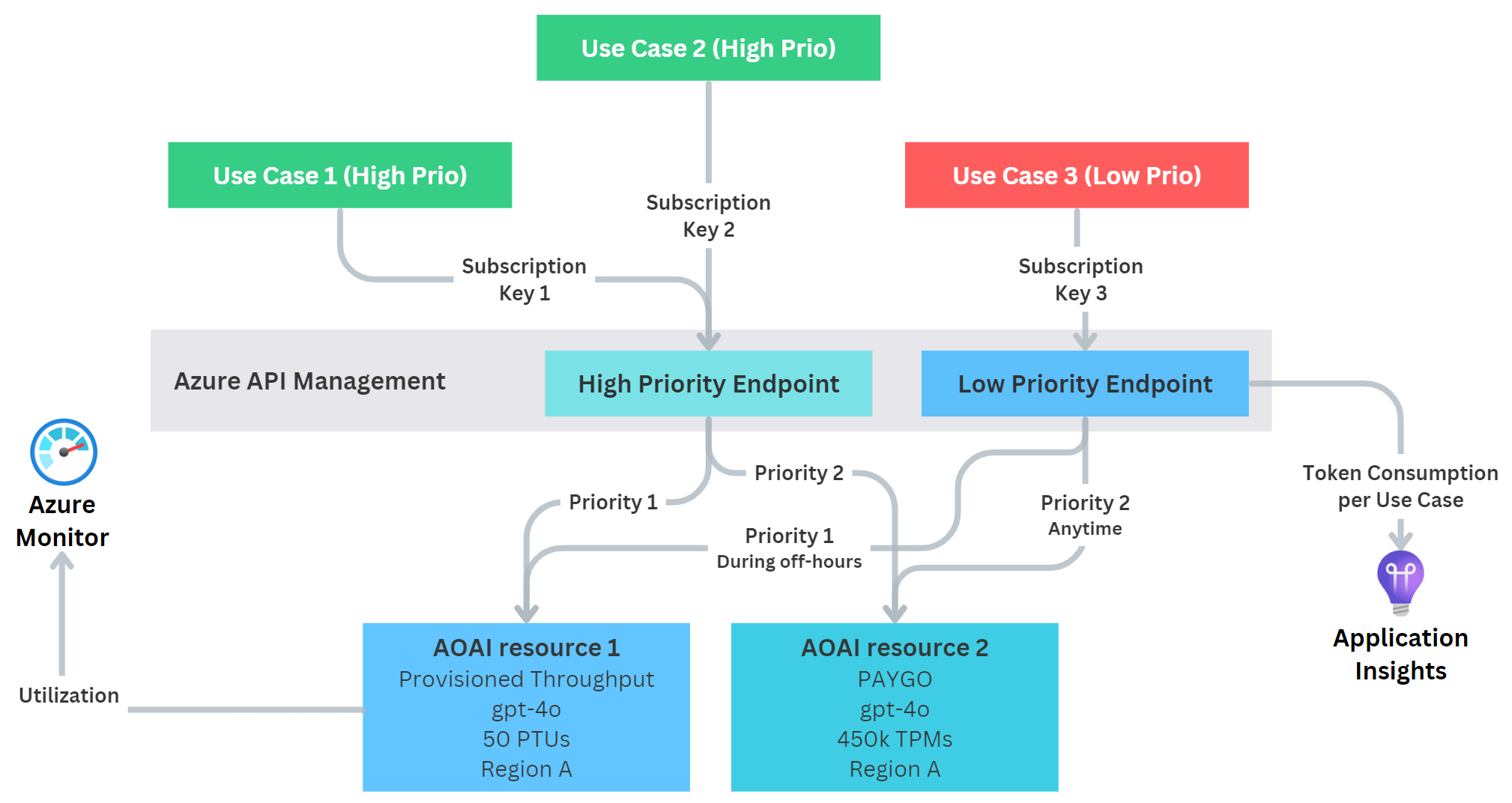
Again, we have two endpoints:
- Our high-priority endpoint that can access all AOAI resources at any time
- Our low-priority endpoint that can only access the PTU during certain times of day or days of the week
With this, we ensure safety for our high-priority workload(s) if a low-priority use case needs to get a workload done during the day (will be routed to PAYGO), but at night it may use the PTU resource as much as needed. Surely, it could still fully hog it, but at least it wouldn’t happen during core business hours.
Solution 3 - Token Limiting #
One additional solution is to limit the amount of tokens a single use case can consume per minute (measured in Tokens per Minute - TPM).
For example, we could say:
- High-priority use cases: No limitations
- Low-priority use cases: 10k TPMs/use case
Using the Azure OpenAI Capacity calculator, we can roughly estimate how much throughput in terms of TPMs we get for a given model per PTU. With this, we can make an educated decision how many TPMs we want to grand to the low-priority use cases. The architecture looks very simple:
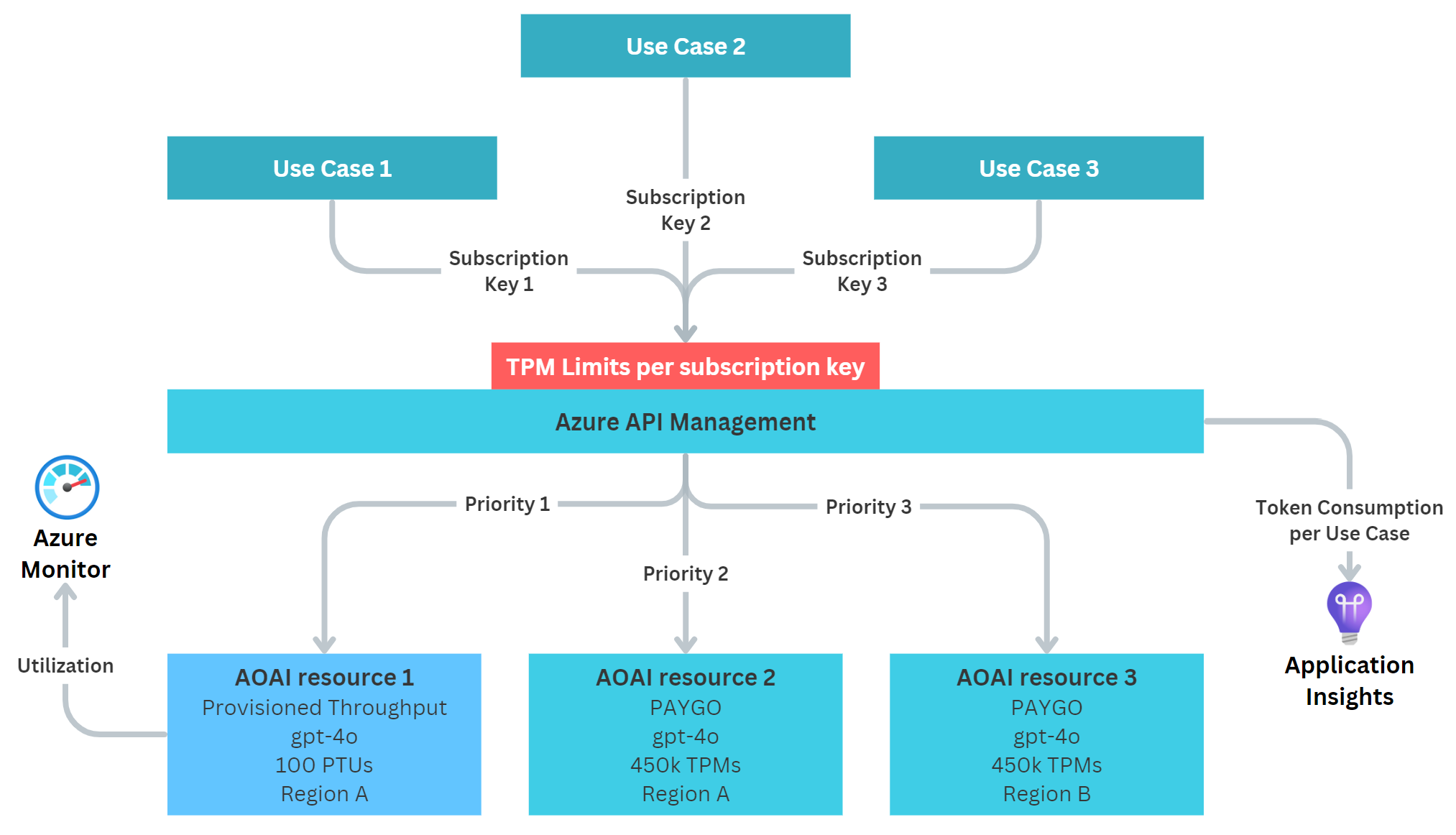
However, this token limit is implemented on the APIM layer, thus it is evaluated as the requests come. This is before APIM routes them to the PTU or PAYGO backends. This means that the token limit is independent of the backends and does not exclusively restrict PTU access, but also potentially PAYGO access.
Solution 4 - A healthy combination #
Lastly, we may combine multiple approaches into one. For example we can combine a time-based approach with the multiple PTU approach:
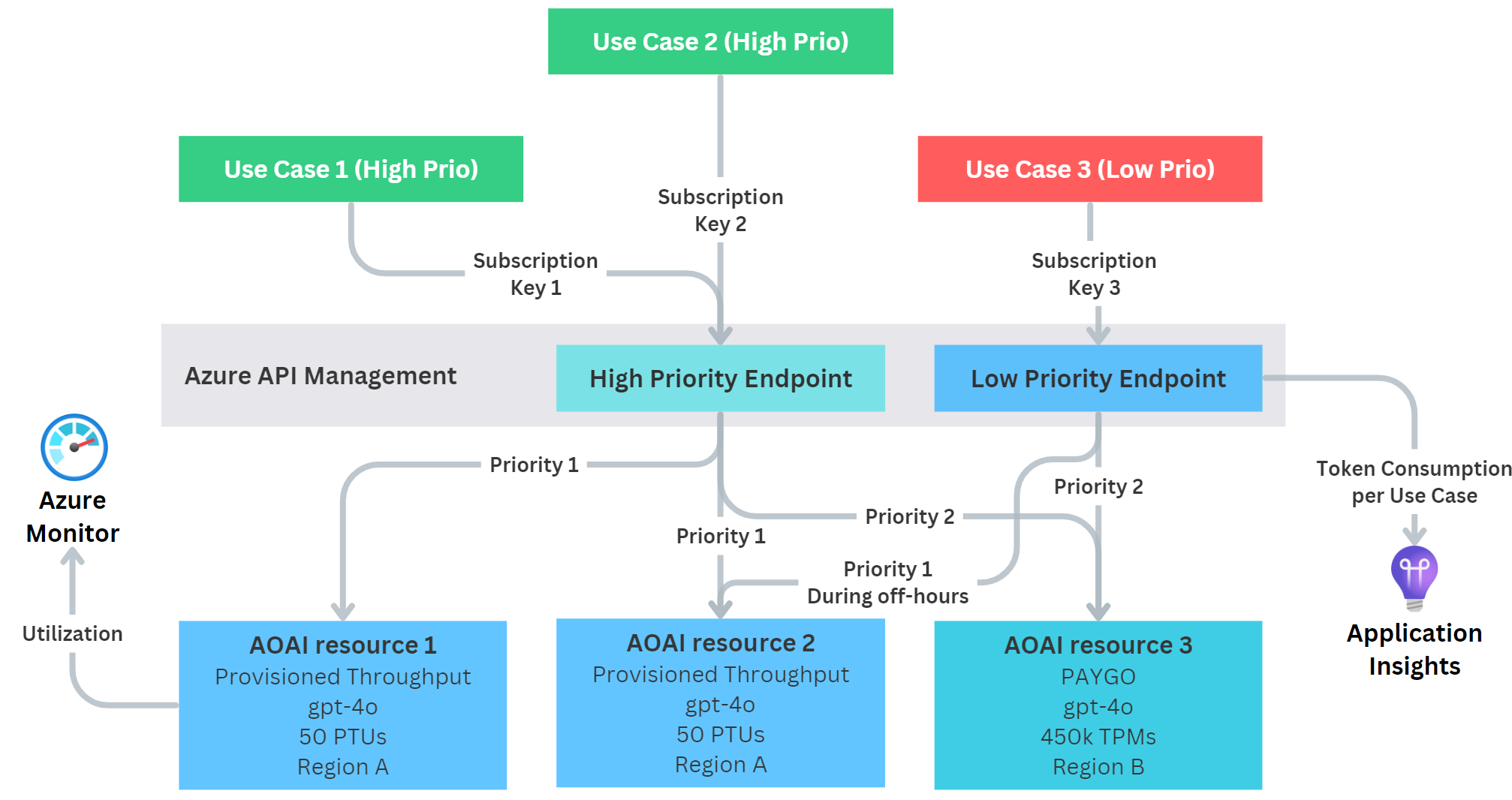
This ensures that during business hours our PTUs can only be used by high-priority use cases. Outside of the business hours, we nevertheless offer some part of them to the low-priority use cases, thus saving cost, while still ensuring smooth operations for occasional requests that are high priority.
Furthermore, we also could combine this with token limiting, but for sake of simplicity this is not shown here.
Implementation #
Let’s discuss how these scenarios can be implemented with APIM.
Enable Token Tracking via Application Insights #
To start tracking token consumption per inference call, we need to first add Application Insights to our APIM instance:
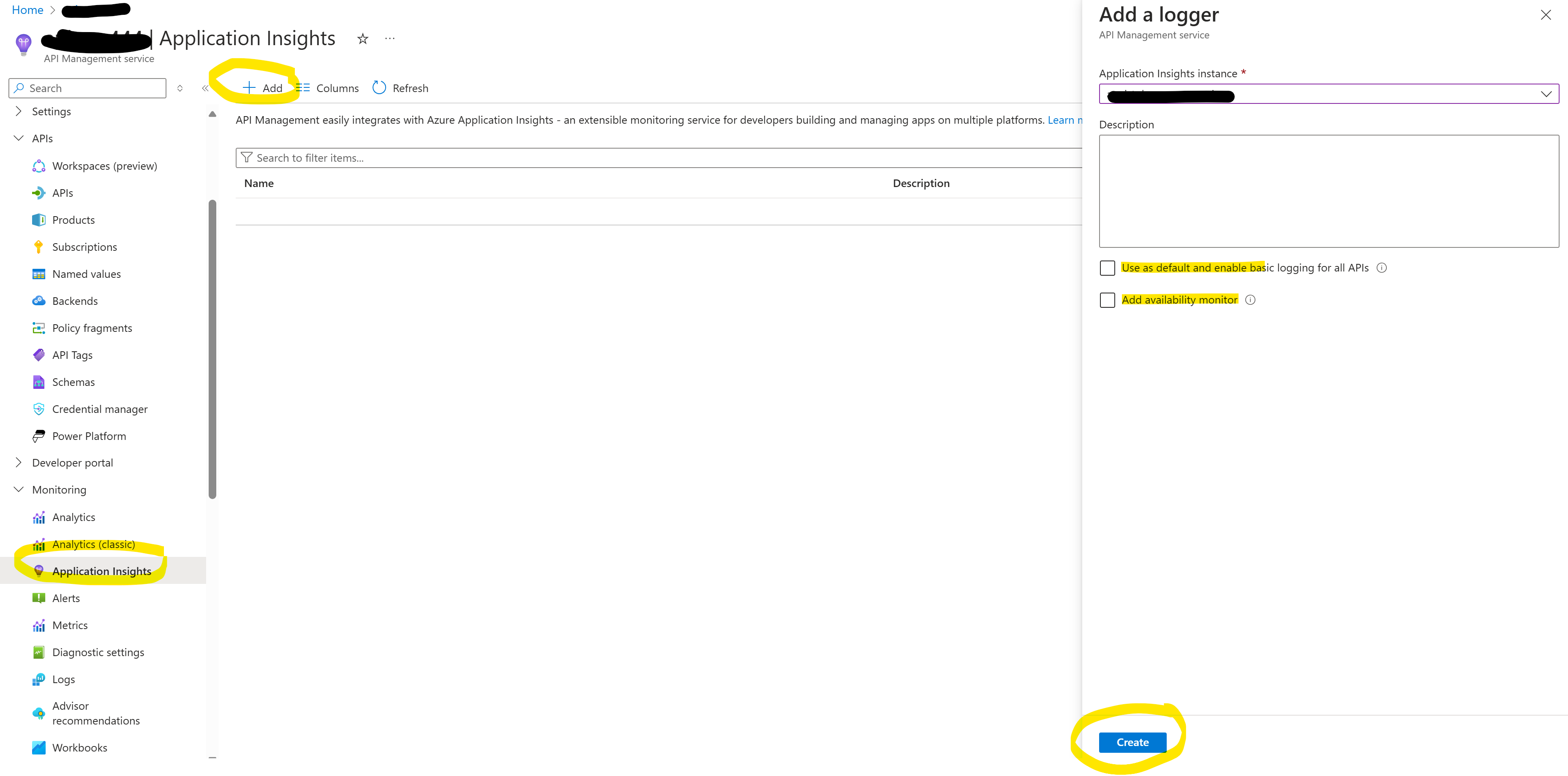
We can disable both settings, as we do not need them:
- Use as default and enable basic logging for all APIs
- Add availability monitor
Next, we want to enable Custom Metrics in Application Insights, otherwise Application Insights won’t accept the incoming token consumption feed from APIM:
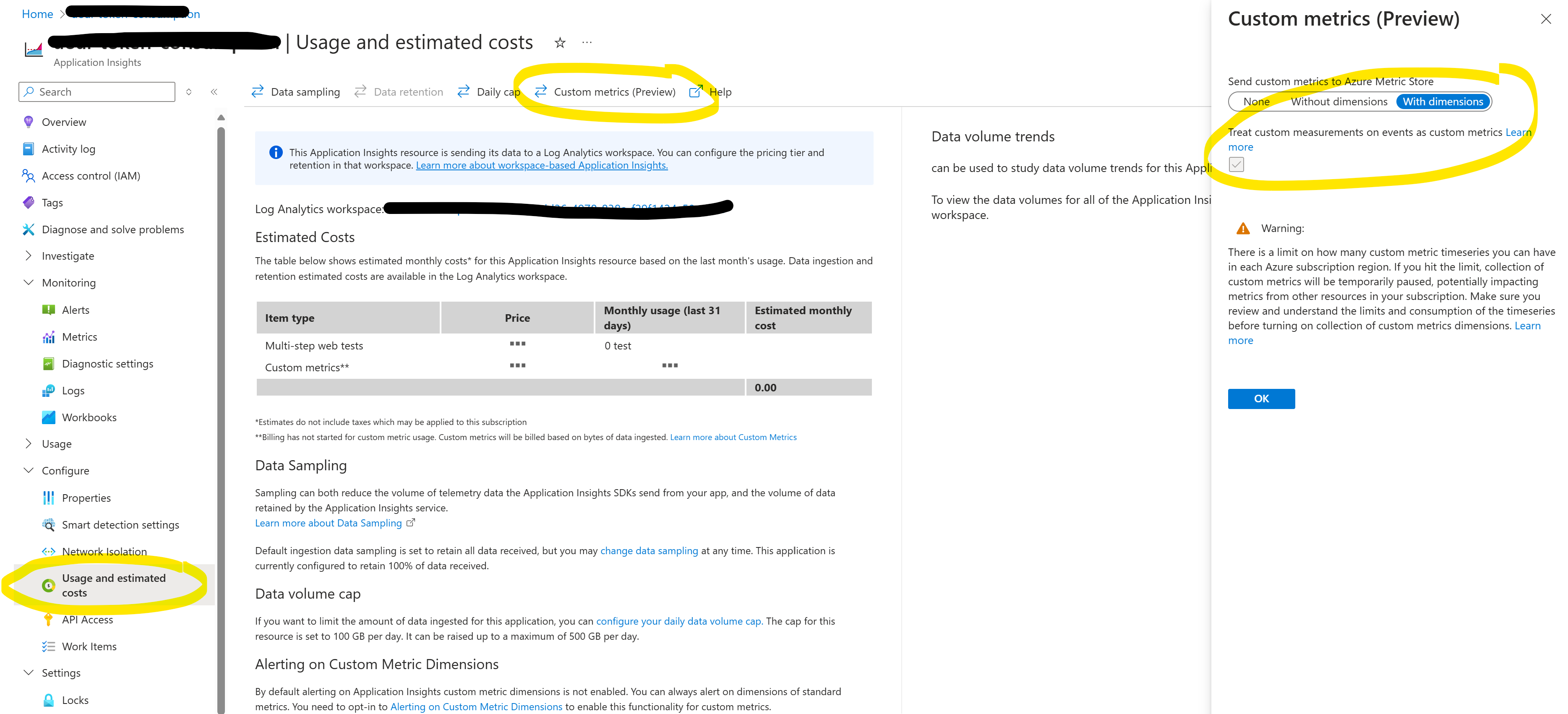
We need to enable With Dimension so we get all the data.
Now, we need to go to All APIs in APIM, select Settings and enable Application Insights for all requests:
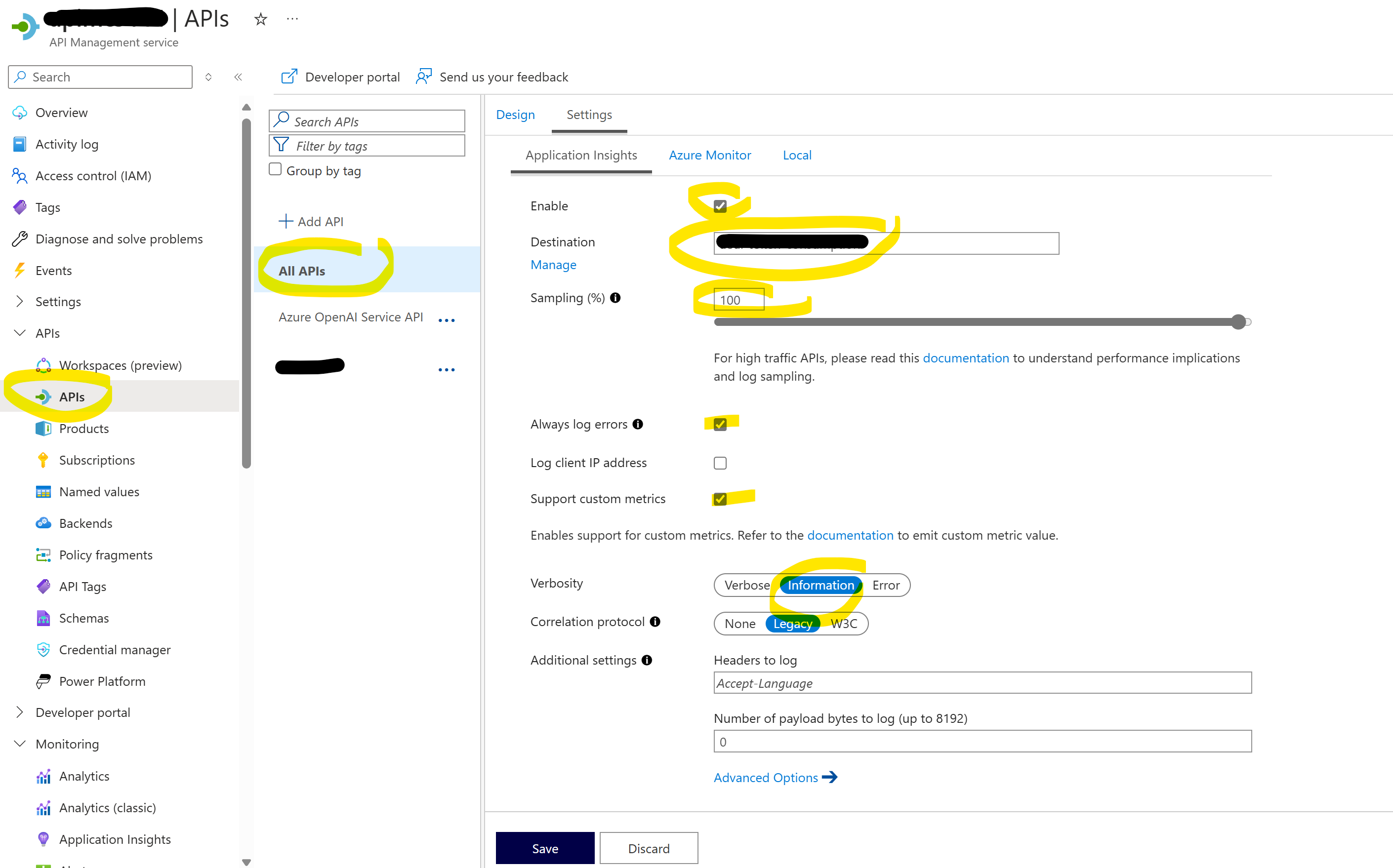
It is important to set:
- Sampling to 100% (otherwise we’ll only track a fraction of the tokens)
- Verbosity to
Information(if we only log errors, we won’t see tokens for the successfully finished calls)
Next, we want to update our APIM policy to emit the token metric (paste it at the end of the <inbound> section):
<azure-openai-emit-token-metric>
<dimension name="SubscriptionId" value="@(context.Subscription.Id)" />
</azure-openai-emit-token-metric>
A complete policy example can be found here.
Then, we can configure multiple subscription keys. In this case, the name will be used during logging of the tokens:
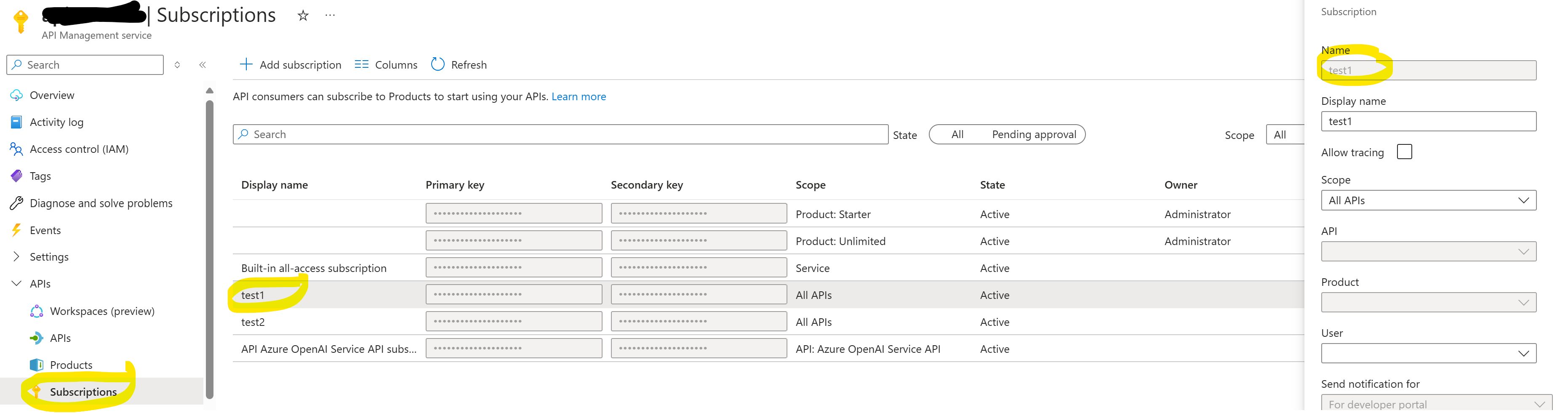
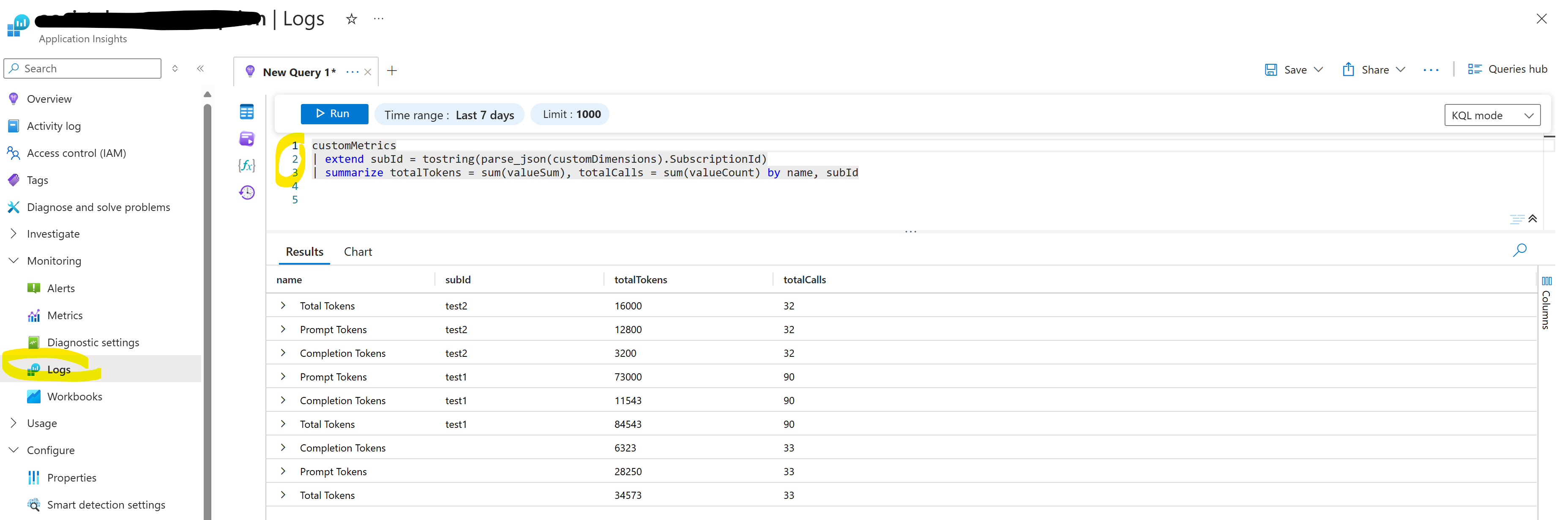
Lastly, after firing a few API calls, we can go Log Analytics and query our customMetrics table:
customMetrics
| extend subId = tostring(parse_json(customDimensions).SubscriptionId)
| summarize totalTokens = sum(valueSum), totalCalls = sum(valueCount) by name, subId
If everything worked out, we should see the token consumption per subscription name:
Configure time-based routing #
To configure time-based routing, we need to add a new attribute in our endpoint configuration to indicate that a certain resource (e.g., PTU) is not allowed during certain time-windows:
backends.Add(new JObject()
{
{ "url", "https://abcdefg.openai.azure.com/" },
{ "priority", 1},
{ "isThrottling", false },
{ "retryAfter", DateTime.MinValue } ,
{ "hasTimeRestriction", true }
});
And then in our backend selection code, we check if the current time falls outside the defined window:
...
<set-variable name="backendIndex" value="@{
// define during which times we want the PTU to be accessible
bool IsWithinAllowedHours()
{
TimeZoneInfo timeZoneInfo = TimeZoneInfo.FindSystemTimeZoneById("W. Europe Standard Time");
DateTime currentTime = TimeZoneInfo.ConvertTimeFromUtc(DateTime.UtcNow, timeZoneInfo);
TimeSpan startTime = new TimeSpan(8, 0, 0);
TimeSpan endTime = new TimeSpan(22, 0, 0);
return !(currentTime.TimeOfDay >= startTime && currentTime.TimeOfDay <= endTime);
}
JArray backends = (JArray)context.Variables["listBackends"];
bool isWithinAllowedHours = IsWithinAllowedHours();
int selectedPriority = Int32.MaxValue;
List<int> availableBackends = new List<int>();
for (int i = 0; i < backends.Count; i++)
{
JObject backend = (JObject)backends[i];
if (!backend.Value<bool>("isThrottling"))
{
int backendPriority = backend.Value<int>("priority");
bool hasTimeRestriction = backend.Value<bool?>("hasTimeRestriction") ?? false;
// Check the time condition for the backend with time restriction
if (hasTimeRestriction && !isWithinAllowedHours)
{
continue; // Skip this backend if it's restricted by time and we're not within the allowed hours
}
...
A full policy example can be found here.
Configure token limiting #
To limit the amount of tokens a use case can consume per minute, we can leverage the new azure-openai-token-limit statement in APIM. So in our <inbound> policy, we can use an choose statement to define an azure-openai-token-limit per subscription id:
<choose>
<when condition="@(context.Subscription.Id.Equals("UseCase1"))">
<azure-openai-token-limit counter-key="@(context.Subscription.Id)" tokens-per-minute="50000" estimate-prompt-tokens="false" remaining-tokens-header-name="x-tokens-remaining" tokens-consumed-header-name="x-tokens-consumed" remaining-tokens-variable-name="remainingTokens" />
</when>
<when condition="@(context.Subscription.Id.Equals("UseCase2"))">
<azure-openai-token-limit counter-key="@(context.Subscription.Id)" tokens-per-minute="10000" estimate-prompt-tokens="false" remaining-tokens-header-name="x-tokens-remaining" tokens-consumed-header-name="x-tokens-consumed" remaining-tokens-variable-name="remainingTokens" />
</when>
</choose>
In this example, use case 1 receives 50k TPMs, while use case 2 only receives 10k TPMs. If we do not specify a limit for a given subscription, it will just give it unlimited throughput. And yes, this code heavily should be made much less repetitive!
Summary #
Sharing multiple use cases on one PTU deployment is definitively possible, but requires good planning and also making a few tradeoffs. In this post we’ve went through several approaches, that together, can get us to a (hopefully) well functioning solution.