Securely deploying Deepseek R1 on Azure Machine Learning
Table of Contents
Introduction #
In this post, we’ll explain how to deploy Deepseek R1 via vLLMs using Azure Machine Learning’s Managed Online Endpoints for efficient, scalable, and secure real-time inference. This has the benefit that the model is running within your own Azure subscription and you’re in full control of what is happening to your data. For example, this allows to deploy R1 within a region of the US or EU, e.g., eastus2, swedencentral or others.
In detail, we’ll be deploying DeepSeek-R1-Distill-Llama-8B, which is based off Llama-3.1-8B.
![]()
Tools used #
To deploy R1, we’ll be using:
- vLLM
- Managed Online Endpoints in Azure Machine Learning
Here’s a short summary of what those two components do:
Introduction to vLLM #
vLLM is a high-throughput and memory-efficient inference and serving engine designed for large language models (LLMs). It optimizes the serving and execution of LLMs by utilizing advanced memory management techniques, such as PagedAttention, which efficiently manages attention key and value memory. This allows for continuous batching of incoming requests and fast model execution, making vLLM a powerful tool for deploying and serving LLMs at scale.
vLLM supports seamless integration with popular Hugging Face models and offers various decoding algorithms, including parallel sampling and beam search. It also supports tensor parallelism and pipeline parallelism for distributed inference, making it a flexible and easy-to-use solution for LLM inference (see full docs).
Managed Online Endpoints in Azure Machine Learning #
Managed Online Endpoints in Azure Machine Learning provide a streamlined and scalable way to deploy machine learning models for real-time inference. These endpoints handle the complexities of serving, scaling, securing, and monitoring models, allowing us to focus on building and improving your models without worrying about infrastructure management.
Deepseek R1 model deployment #
Let’s go through deploying R1 on Azure Machine Learning’s Managed Online Endpoints. For this, we’ll use a custom Dockerfile and configuration files to set up the deployment. As a model, we’ll be using deepseek-ai/DeepSeek-R1-Distill-Llama-8B on a single Standard_NC24ads_A100_v4 instance.
Step 1: Create a custom Environment for vLLM on AzureML #
First, we create a Dockerfile to define the environment for our model. For this, we’ll be using vllm’s base container that has all the dependencies and drivers included:
FROM vllm/vllm-openai:latest
ENV MODEL_NAME deepseek-ai/DeepSeek-R1-Distill-Llama-8B
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server --model $MODEL_NAME $VLLM_ARGS
The idea here is that we can pass a model name via an ENV variable, so that we can easily define which model we want to deploy during deployment time.
Next, we log into our Azure Machine Learning workspace:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Now, we create an environment.yml file to specify the environment settings:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: r1
build:
path: .
dockerfile_path: Dockerfile
Then let’s build the environment:
az ml environment create -f environment.yml
Step 2: Deploy the AzureML Managed Online Endpoint #
Time for deployment, so let’s first create an endpoint.yml file to define the Managed Online Endpoint:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: r1-prod
auth_mode: key
Let’s create it:
az ml online-endpoint create -f endpoint.yml
For the next step, we’ll need the address of the Docker image address we created. We can quickly get it from AzureML Studio -> Environments -> r1:
Finally, we create a deployment.yml file to configure the deployment settings and deploy our desired model from HuggingFace via vLLM:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: current
endpoint_name: r1-prod
environment_variables:
MODEL_NAME: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
VLLM_ARGS: "" # optional args for vLLM runtime
environment:
image: xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx # paste Docker image address here
inference_config:
liveness_route:
port: 8000
path: /ping
readiness_route:
port: 8000
path: /health
scoring_route:
port: 8000
path: /
instance_type: Standard_NC24ads_A100_v4
instance_count: 1
request_settings: # This section is optional, yet important for optimizing throughput
max_concurrent_requests_per_instance: 32
request_timeout_ms: 60000
liveness_probe:
initial_delay: 10
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
readiness_probe:
initial_delay: 120 # wait for 120s before we start probing, so the model can load peacefully
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
Some notes on the parameter choices that we should consider when deploying this:
instance_count- defines how many nodes ofStandard_NC24ads_A100_v4we want to spin up.max_concurrent_requests_per_instance- defines how many concurrent requests we’ll let pass through the endpoint into the queue before returning aHTTP 429.request_timeout_ms- amount of milliseconds that can pass, until the endpoint closes the connection. In our case here, the client will receive aHTTP 408after waiting for 60 seconds.
Changing these parameters will have the following impact:
- Increasing
max_concurrent_requests_per_instancewill increase overall throughput and TPMs (tokens per minute), but will also increase total latency for a given call. - Increasing
request_timeout_mswill allow clients to wait longer for a response, given thatmax_concurrent_requests_per_instancehas not been exhausted yet. - Increasing
instance_countwill linearly scale throughput and cost.
A full explanation of the parameters can be found in my prior post Deploying vLLM models on Azure Machine Learning with Managed Online Endpoints .
Lastly, we can deploy the r1 model:
az ml online-deployment create -f deployment.yml --all-traffic
By following these steps, we have deployed a HuggingFace model on Azure Machine Learning’s Managed Online Endpoints, ensuring efficient and scalable real-time inference. Time to test it!
Step 2: Testing the deployment #
First, let’s get the endpoint’s scoring uri and the api keys:
az ml online-endpoint show -n r1-prod
az ml online-endpoint get-credentials -n r1-prod
For completion models, we can then call the endpoint using this Python code snippet:
import requests
url = "https://r1-prod.polandcentral.inference.ml.azure.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer xxxxxxxxxxxx"
}
data = {
"model": "deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"messages": [
{
"role": "user",
"content": "What is better, summer or winter?"
},
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
Answer looks good, we can see the <think> tags where the model does its reasoning:
{
"id":"chatcmpl-ccf51218-30a0-4200-bfa4-5d90ac1fdd98",
"object":"chat.completion",
"created":1738058980,
"model":"deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"choices":[
{
"index":0,
"message":{
"role":"assistant",
"content":"<think>\nHmm, the user is asking whether summer or winter is better. I need to consider various aspects to make the answer... that both seasons have their pros and cons, and it's about what you value more.\n</think>\n\nThe debate between summer and winter is subjective and depends on personal preferences. Here's a breakdown of each season's characteristics:\n\n### Summer:\n- **Weather**: Generally hotter and longer days, ideal for beach activities, hiking, and outdoor sports.\n- **Nature**: Blooms with flowers, greenery, and fruit ripening; many animals are active.\n- **Events**: Festivals, concerts, and seasonal events like Independence Day.\n- **Challenges**: Hotter temperatures can be uncomfortable indoors; some people find it harder to sleep in the heat.\n\n### Winter:\n- **Weather**: Cooler temperatures, shorter days, and potentially snowy conditions.\n- **Nature**: Fewer bugs, quieter wildlife; plants slow down growth; fewer daylight hours can affect mood.\n- **Events**: Holidays like Christmas, winter festivals, and activities like skiing or snowboarding.\n- **Challenges**: Cold weather can be inconvenient; Infrastructure issues like slippery roads and closed schools.\n\n### Neutral Considerations:\n- **Light and Mood**: Summer's extended daylight can boost energy, while winter's earlier sunset may lead to a more restful environment.\n- **Comfort**: Summer can feel stuffy indoors; winter may require more layers but can feel cozy at home.\n\n### Conclusion:\nBoth seasons have their highs and lows, and the choice between summer and winter is largely a matter of personal preference. If you enjoy outdoor activities, parties, and vibrant social scenes, summer might be your pick. If you prefer a quieter, more introspective time, winter can be more appealing. Ultimately, the better season depends on what you're searching for.",
"tool_calls":[
]
},
"logprobs":"None",
"finish_reason":"stop",
"stop_reason":"None"
}
],
"usage":{
"prompt_tokens":11,
"total_tokens":553,
"completion_tokens":542,
"prompt_tokens_details":"None"
},
"prompt_logprobs":"None"
}
Works! Lastly, we can also use the OpenAI SDK to perform streaming:
from openai import OpenAI
url = "https://r1-prod.polandcentral.inference.ml.azure.com/v1"
client = OpenAI(base_url=url, api_key="xxxxxxxx")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
messages=[
{"role": "user", "content": "What is better, summer or winter?"},
],
stream=True
)
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "content"):
print(delta.content, end="", flush=True)
Monitoring our deployment #
We can also monitor the resource utilization, most importantly obviously the GPUs via Azure Monitor, as outline here. When putting constant load on the model, we see that vLLM eats up 90% of the GPU memory (default setting) and we see GPU utilization close to 100%:
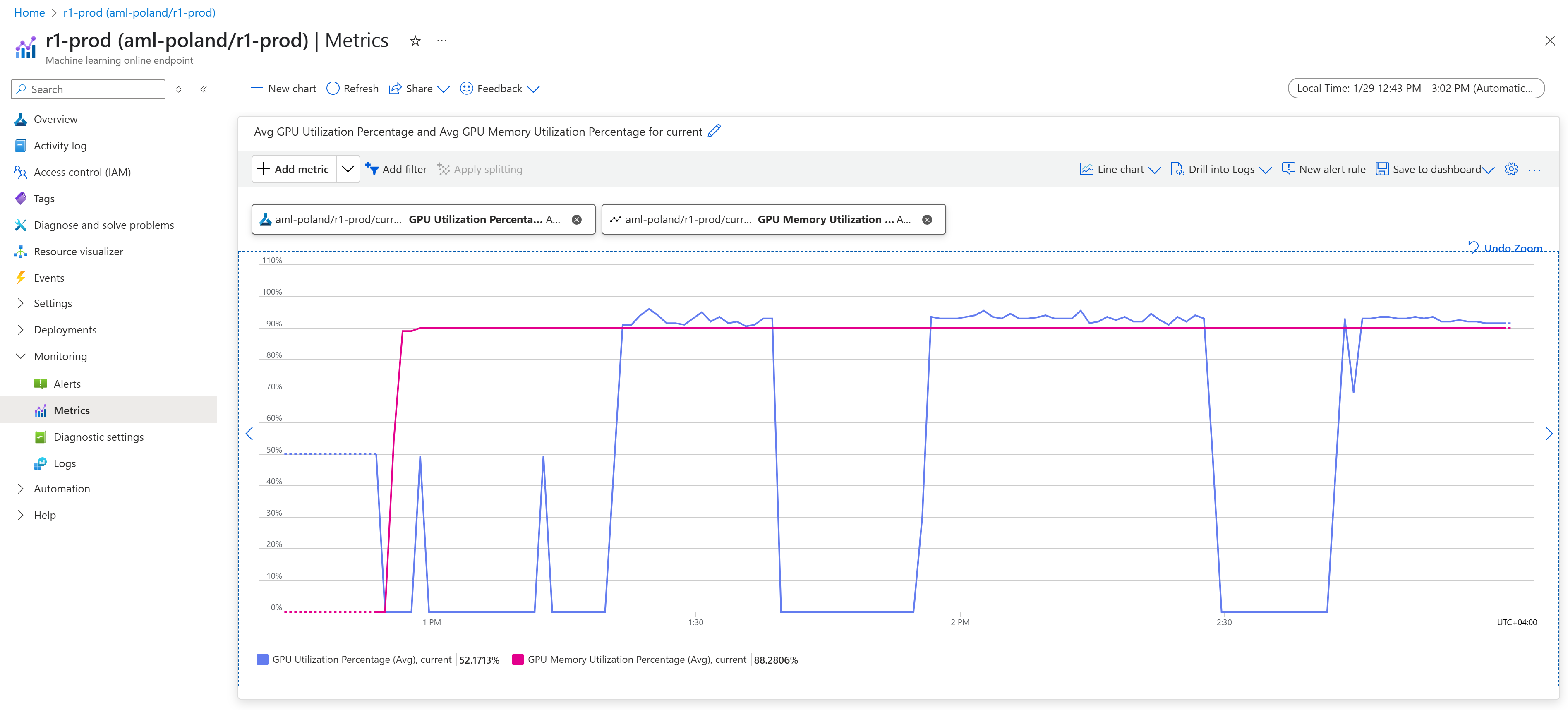
Autoscaling our Deepseek R1 deployment #
Autoscaling Managed Online Endpoint deployments in Azure Machine Learning allows us to dynamically adjust the number of instances allocated to our endpoints based on real-time metrics and schedules. This ensures that our application can handle varying loads efficiently without manual intervention. By integrating with Azure Monitor, you can set up rules to scale out when the CPU or GPU utilization exceeds a certain threshold or scale in during off-peak hours. For detailed guidance on configuring autoscaling, you can refer to the official documentation.
Summary #
In this post, we’ve discussed how to deploy the 8bn parameter version of Deepseek’s R1 model to Azure Machine Learning’s Managed Online Endpoints for efficient real-time inference. This allowed us to use R1 in a secure, private environment where we have full control over the data and full model ownership. Furthermore, this allowed us to run the model in an Azure region of our choice, e.g., in a US- or EU-based Azure data center.