Deploying BGE-M3 and other embedding models on Azure Machine Learning with Managed Online Endpoints
Table of Contents
Introduction #
In this post, we’ll explain how to deploy an embedding model like BGE-M3 on Azure Machine Learning’s Managed Online Endpoints for efficient, scalable, and secure real-time embedding vector creation. Many embedding models, including BGE-M3 are available on “Models-as-a-Platform” on Azure AI Studio and can be deployed with a few clicks. However, in this guide we’ll do it the “manual” way, which allows us to easier automate the deployment (LLMOps) and gives us more choice when it comes to deploying the model on smaller VM/GPU types, e.g. a T4 GPU, instead of an A100.
Managed Online Endpoints in Azure Machine Learning #
Managed Online Endpoints in Azure Machine Learning provide a streamlined and scalable way to deploy machine learning models for real-time inference. These endpoints handle the complexities of serving, scaling, securing, and monitoring models, allowing us to focus on building and improving your models without worrying about infrastructure management.
Deployment Steps #
Authoring our scoring script for inference #
Firstly, let’s write a short score.py script that we’ll run on our inference server on Managed Online Endpoints:
import json
import logging
from FlagEmbedding import BGEM3FlagModel
def init():
global model
logging.info("Loading model from web...")
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
logging.info("Init complete")
def run(raw_data):
data = json.loads(raw_data)["input"]
embeddings = model.encode(data, batch_size=12, max_length=8192)
logging.info(f"Embeddings: {embeddings}")
return embeddings['dense_vecs'].tolist()
The code is quite simple:
init()- loads the model using theFlagEmbeddinglibraryrun()- takes in a JSON document with an array calledinput, which contains a list of strings that need to be embedded.
Now, to run this code, we’ll need to define our dependencies in conda.yml:
name: model-env
channels:
- conda-forge
dependencies:
- python=3.10
- numpy
- pip=23.0.1
- scikit-learn
- scipy
- pip:
- azureml-defaults
- inference-schema[numpy-support]
- joblib
- FlagEmbedding
- peft
Managed Online Endpoint deployment steps #
Time to get started with our deployment, so let’s log into our Azure Machine Learning workspace:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Next, we can create our Managed Online Endpoint endpoint.yml definition:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: bge
auth_mode: key
Then let’s do the same for the deployment deployment.yml, which will be running inside our endpoint:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: current
endpoint_name: bge
code_configuration:
code: .
scoring_script: score.py
environment:
conda_file: conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.8-cudnn8-ubuntu22.04:latest
instance_type: Standard_NC4as_T4_v3
instance_count: 1
request_settings:
max_concurrent_requests_per_instance: 16
request_timeout_ms: 10000
Here, we’re using mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.8-cudnn8-ubuntu22.04:latest as our base inference image. This image contains cuda, so we can direclty leverage the T4 GPUs of our Standard_NC4as_T4_v3 instance. The full list of base images can be found under Azure/AzureML-Containers.
For handling concurrency, we will need to find a good value for max_concurrent_requests_per_instance. In our case, we’ve chosen 16, which means API consumers will get a HTTP 429 in case more than 16 requests are being queued at a given point in time. By tuning this, we can optimize the throughput/latency curve. However, this value heavily depends on the SKU instance we’re using for the deployment. We’ll discuss this more in the testing phase below.
Finally, let’s create the deployment using:
az ml online-endpoint create -f endpoint.yml
az ml online-deployment create -f deployment.yml --all-traffic
This will:
- Create the “empty” Managed Online Endpoint
- Automatically bake the conda environment into the
azureml/openmpi4.1.0-cuda11.8-cudnn8-ubuntu22.04:latestbase image - Deploy the newly created image to an managed
Standard_NC4as_T4_v3instance with ourscore.pyscript inside of it
Testing the deployment #
So let’s test the endpoint. First, we’ll need to get the endpoint’s scoring uri and the API keys:
az ml online-endpoint show -n bge
az ml online-endpoint get-credentials -n beg
For our embedding model, we can then call the endpoint using this Python code snippet:
import json
import requests
url = "https://bge.polandcentral.inference.ml.azure.com/score"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxx"
}
data = {
"input": ["Hello World", "This is just a test for another text"]
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.status_code)
print(response.json())
Response:
[[-0.05633544921875, ..., 0.01433563232421875], [-0.0546875, ..., 0.00677490234375]]
Works!
So, let’s finally put some load on the model and see how it performs. In our case, I’m running the following workload profile:
max_concurrent_requests_per_instanceset to16- Single
Standard_NC4as_T4_v3instance - ~2000 input tokens during the test
- 16 threads in parallel
- 10k inference calls
Once we run this sustained for a few minutes, we can see the following curve in the Azure Portal (under our endpoint in the Metrics tab):
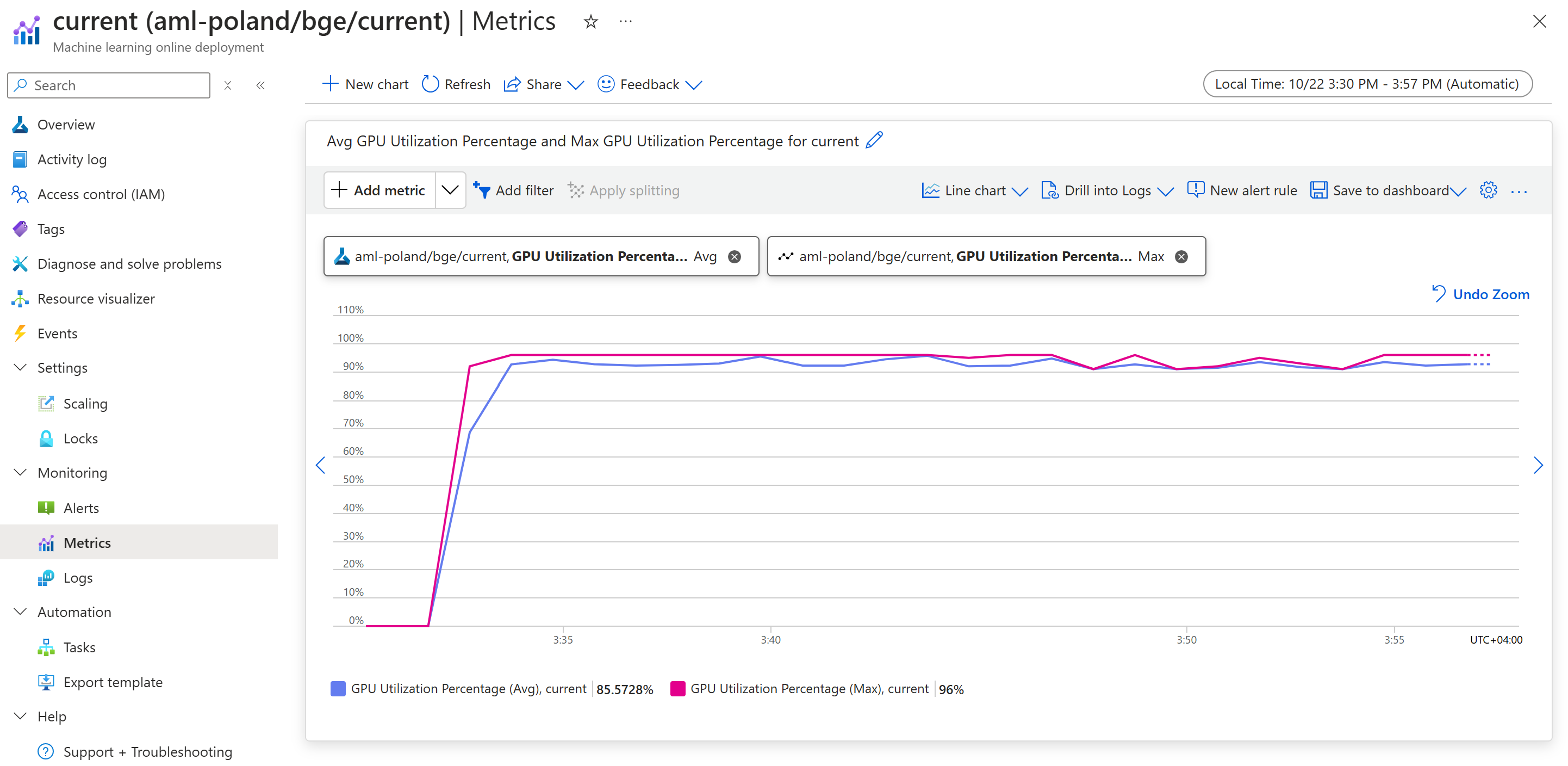
Not fully utilized, but we’re getting close to a 100% GPU utilization. From here, we can tune our endpoint for more throughput.
Autoscaling our embedding endpoint #
Autoscaling Managed Online Endpoint deployments in Azure Machine Learning allows us to dynamically adjust the number of instances allocated to our endpoints based on real-time metrics and schedules. This ensures that our application can handle varying loads efficiently without manual intervention. By integrating with Azure Monitor, you can set up rules to scale out when the CPU or GPU utilization exceeds a certain threshold or scale in during off-peak hours. For detailed guidance on configuring autoscaling, you can refer to the official documentation.
Summary #
In this post, we’ve discussed how to deploy embedding models like BGE-M3 using Azure Machine Learning’s Managed Online Endpoints for efficient real-time inference. The guide outlined the steps for creating the required score.py and conda.yml assets, then defining the endpoint, and deploying our model using Azure CLI commands. We also looked at examples for testing the deployed model.