Using Azure Search for vector search with Azure OpenAI and LangChain
Table of Contents
Introduction #
Recently, Azure Cognitive Search introduced vector search for indexing, storing, and retrieving vector embeddings from a search index. In this post, we’ll look into how we can use this to chat with your private data, similar to ChatGPT. So besides Azure Cognitive Search we’ll be using LangChain and Azure OpenAI Service. As the underlying Large Language Model, we’ll be using gpt-3.5-turbo (the “ChatGPT” model).
Tutorial #
First, create a .env and add your Azure OpenAI Service details and Azure Cognitive Search details:
OPENAI_API_BASE=https://xxxxxxxx.openai.azure.com/
OPENAI_API_KEY=xxxxxx
OPENAI_API_VERSION=2023-05-15
AZURE_COGNITIVE_SEARCH_SERVICE_NAME=https://xxxxxxx.search.windows.net
AZURE_COGNITIVE_SEARCH_API_KEY=xxxxxx
AZURE_COGNITIVE_SEARCH_INDEX_NAME=xxxxxx
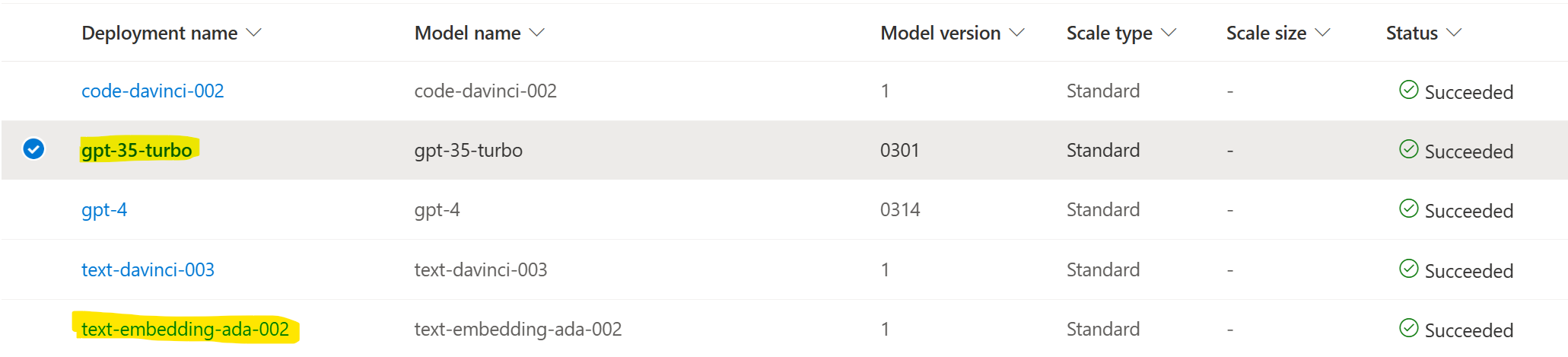
Next, make sure that you have gpt-35-turbo and text-embedding-ada-002 deployed and used the same name as the model itself for the deployment.
Let’s install the latest versions of openai, langchain, and azure-search-documents (which is used under the hood by LangChain) via pip:
pip install openai --upgrade
pip install langchain --upgrade
pip install azure-search-documents --pre --upgrade
For azure-search-documents, we need the preview version, as only this one includes vector search capabilities. In this post, we’re using openai==0.27.8, langchain==0.0.245, and azure-search-documents==11.4.0b6.
Ok, let’s start writing some code. First, let’s initialize our Azure OpenAI Service connection, create the LangChain objects, and create our Azure Search connection:
import os
import openai
from dotenv import load_dotenv
from langchain.chat_models import AzureChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import AzureSearch
from langchain.document_loaders import DirectoryLoader
from langchain.document_loaders import TextLoader
from langchain.text_splitter import TokenTextSplitter
from langchain.chains import ConversationalRetrievalChain
from langchain.prompts import PromptTemplate
# Load environment variables
load_dotenv()
# Configure OpenAI API
openai.api_type = "azure"
openai.api_base = os.getenv('OPENAI_API_BASE')
openai.api_key = os.getenv('OPENAI_API_KEY')
openai.api_version = os.getenv('OPENAI_API_VERSION')
# Initialize gpt-35-turbo and our embedding model
llm = AzureChatOpenAI(deployment_name="gpt-35-turbo")
embeddings = OpenAIEmbeddings(deployment_id="text-embedding-ada-002", chunk_size=1)
# Connect to Azure Cognitive Search
acs = AzureSearch(azure_search_endpoint=os.getenv('AZURE_COGNITIVE_SEARCH_SERVICE_NAME'),
azure_search_key=os.getenv('AZURE_COGNITIVE_SEARCH_API_KEY'),
index_name=os.getenv('AZURE_COGNITIVE_SEARCH_INDEX_NAME'),
embedding_function=embeddings.embed_query)
If the Azure Search index does not exist yet, it will be created automatically.
Next, we can load up a bunch of text files, chunk them up and embed them. LangChain supports a lot of different document loaders, which makes it easy to adapt to other data sources and file formats. You can download the sample data here.
loader = DirectoryLoader('data/qna/', glob="*.txt", loader_cls=TextLoader, loader_kwargs={'autodetect_encoding': True})
documents = loader.load()
text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# Add documents to Azure Search
acs.add_documents(documents=docs)
Lastly, we can create our document question-answering chat chain. In this case, we specify the condense question prompt, which converts the user’s question to a standalone question (using the chat history), in case the user asked a follow-up question:
# Adapt if needed
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template("""Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:""")
qa = ConversationalRetrievalChain.from_llm(llm=llm,
retriever=acs.as_retriever(),
condense_question_prompt=CONDENSE_QUESTION_PROMPT,
return_source_documents=True,
verbose=False)
Let’s ask a question:
chat_history = []
query = "what is Azure OpenAI Service?"
result = qa({"question": query, "chat_history": chat_history})
print("Question:", query)
print("Answer:", result["answer"])
From where, we can also ask follow up questions:
chat_history = [(query, result["answer"])]
query = "Which regions does the service support?"
result = qa({"question": query, "chat_history": chat_history})
print("Question:", query)
print("Answer:", result["answer"])
This should yield the following (or similar) output (btw, this information is outdated!):
Question: what is Azure OpenAI Service?
Answer: Azure OpenAI Service is a service provided by Microsoft that gives users access to OpenAI's language models such as GPT-3, Codex and Embeddings series. Users can access the service through REST APIs, Python SDK, or our web-based interface in the Azure OpenAI Studio. The service can be used for content generation, summarization, semantic search, and natural language to code translation. Azure OpenAI offers private networking, regional availability, and responsible AI content filtering. Access to the service is currently limited due to high demand and upcoming product improvements.
Question: Which regions does the service support?
Answer: Azure OpenAI Service is currently available in the East US, South Central US, and West Europe regions.
Looks good! Since we use the follow-up question prompt, LangChain converts the latest question to a follow up question by resolving it via the context.
Summary #
In this blog post, we discussed how we can use Azure Cognitive Search, LangChain, and Azure OpenAI Service to build a ChatGPT-like experience, but over private data. We used embeddings and Azure Cognitive Search to enable the document retrieval step and then used the gpt-3.5-turbo model to generate an answer from the retrieved documents.
Special thanks goes to Fabrizio Ruocco who pushed the PR for Azure Cognitive Search integration to LangChain!