Using Azure Read API for processing many documents at scale
Table of Contents
Introduction #
The Azure Read API allows you to perform OCR on scanned documents of all kinds. This is great for digitalizing contracts, books, or research documents. With support for features like natural reading order support, it can be used for a wide range of tasks.
However, how we can use Azure Read API for processing many documents at scale? Let’s say we need to run 100000 documents through Read API. What is the quickest way that we can do it? What image resolution should we use? What are the tradeoffs we need to consider?
In this post, we’ll look at all these questions and discuss how things like image resolution and parallel processing affect the overall processing time for large OCR jobs.

Image resolution #
Let’s first evaluate if the image resolution makes a difference in terms of processing time and accuracy. For comparing recognition results, we will use the Levenshtein distance to measure the distance between the ground truth of the document and the Read API results.
| Image resolution | Image size | Processing time | Levenshtein distance |
|---|---|---|---|
| 500×667 | 100KB | 1.2s | 11 |
| 1000×1333 | 300KB | 1.5s | 6 |
| 2000×2667 | 1.3MB | 1.7s | 3 |
| 3000×4000 | 3.1MB | 1.9s | 0 |
A few things come to mind when looking at these numbers:
- Larger image resolution gives better results. We can see that Levenshtein distance drops with larger image size, and that is typically the main thing we’ll care about for OCR: the most accuracy recognition results. Azure Read API does not charge extra for larger images, so why not leverage this?
- Larger image resolution only minorly affects processing time. Despite increasing the total pixel count by 35x, processing time increased only by around 1.5x. We do not know for sure, but the Read API most likely performs some image auto-scaling before processing the document.
As a first learning, we should rather use high-resolution images as Read API will produce better OCR results, does not take significantly longer, and most importantly, does not cost more! Next, let’s look at optimizing the overall processing time.
Optimizing processing time #
When calling the Read API, we first have to call the analyze API and then subsequently the analyzeResults API to fetch the results. Obviously, processing will happen in between these two calls. But is there anything else? While we do not know for certain, most likely the following two steps will happen in the backend:
- Upon calling
analyze, our request is first put into a queue (service-side) - An idle worker will fetch our request from the queue an process it
- Upon calling
analyzeResults, the cached results will be returned to us
Again, this is speculation and might not happen exactly like this in reality, but one way or the other, it is very likely that there will be some form of queueing happening. Once unqueued, one of the many workers will process it. Having that said, what is the best strategy to use when having to run OCR on many documents?
To find it out, let’s compare three strategies:
- Option 1 – Sequential: Process each document from start to finish in a gigantic for-loop
- Option 2 – Optimized: First call analyze for a mini-batch of documents in a for-loop (e.g., 100), then start calling analyzeResults for the mini-batch in a for-loop
- Option 3 – Multithreading: Run multiple threads, each thread processes one document from start to finish
Intuitively, we’d suspect that option 3 would be the fastest, followed by option 2, and option 1 should be the slowest. Let’s see if this is actually true!
For testing this, we run the test code from a VM in Azure in the same region as the Read API endpoint. Test documents are stored on Azure Blob in the same region. As Read API is limited to 10 TPS (transactions per second) per default, we add sleep() statement the code to obey that limit. However, this limit can be increased through a support request or alternatively, we could just provision multiple Read API resources. For the multi-threaded test, we run 10 threads in parallel, each sequentially processing 10 documents using its own Cognitive Services resource (=total of 100 TPS).
Let’s look at the results for processing 100 documents in various sizes with the three different approaches:
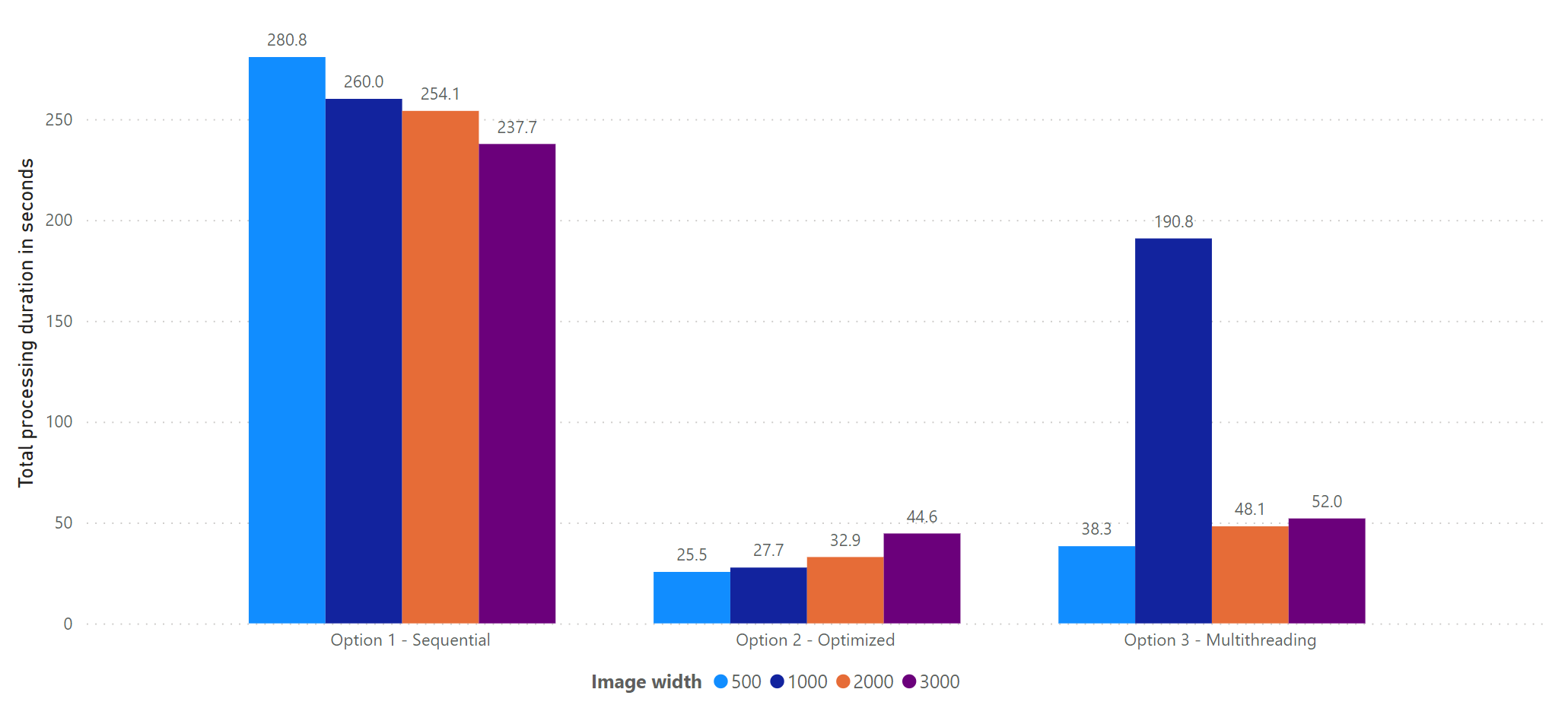
These results look not fully what we expected, so let’s discuss them:
- Same as in our prior tests, image size does not affect processing time in a significant way – everything is within the same ballpark.
- Sequential execution is the slowest. This was expected, as waiting for each document to finish before moving on does not take advantage of the parallel backend of the Read API. Furthermore, we might get a “disadvantageous” position in the queue for each new document.
- Option 2 seems to be the quickest. This seems reasonable, as by starting all analyze calls in one batch, we hopefully will get approximately very similar positions in the queue. Once we start querying for the results, most of them will be finished as they have been processed in parallel by the backend. This results in the overall lowest processing time.
- Using a multi-threaded approach (option 3) did not perform as fast as expected. This is most likely because each thread will process documents one by one. This will result in “disadvantageous” positions in the queue, which makes it inferior to option 2.
- There is some variance in execution time. For option 3, we can see that one of the documents properly got a very deep position in the queue, therefore increasing overall processing time significantly.
Let’s look at the average processing time per document:
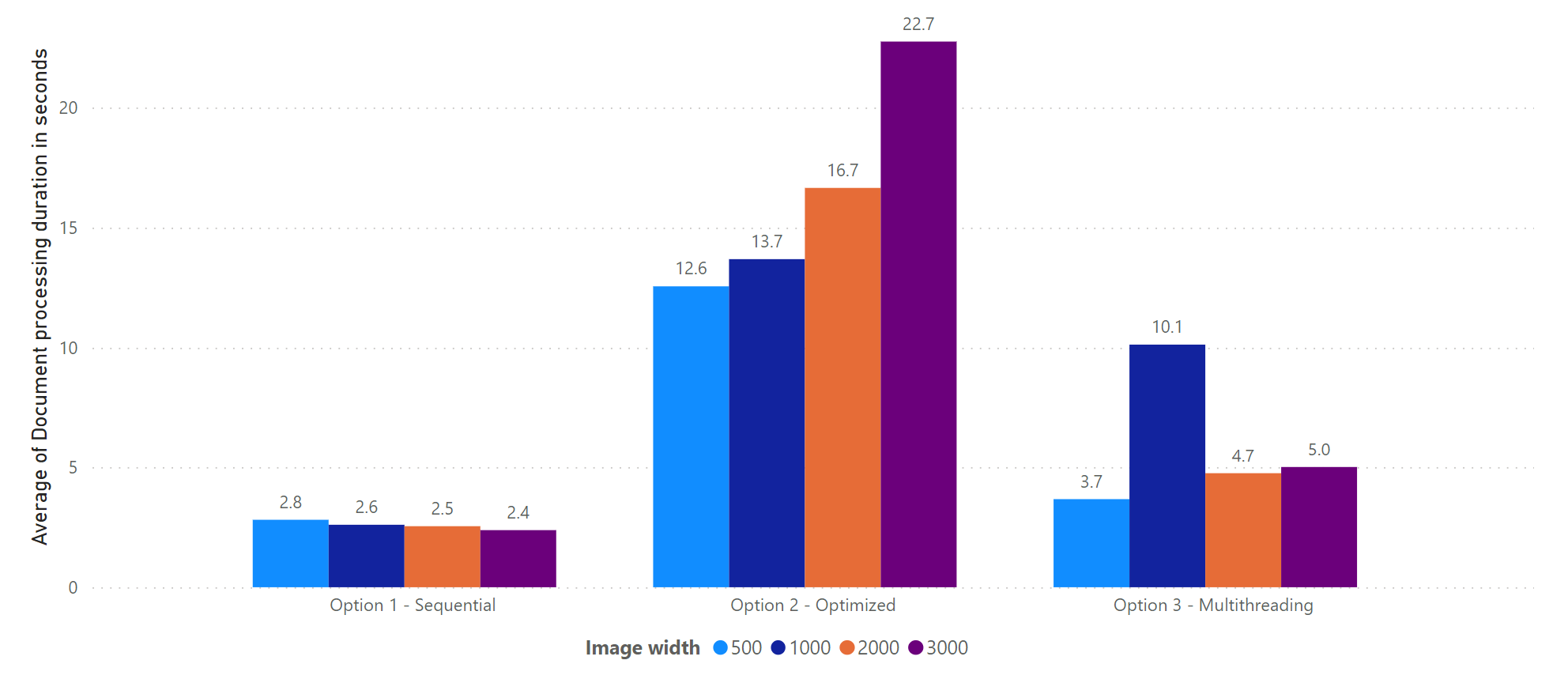
Again, these results look a bit different to what we’ve probably expected:
- There is a large inconstancy in the average processing time. For option 1 and option 3, we should see comparable numbers, but it looks like when the tests for option 3 were executed, the queues was “more busy” than during the first test.
- Average processing time for option 2 is obviously much slower. This seems weird, as we expect a FIFO approach by Read API, but it could have been that a document or
analyzeResultrequest “got stuck”, hence blocking the for-loop.
When it comes to learnings, we can see that using an optimized sequential approach where we decouple the analyze and analyzeResult calls provides the overall quickest processing times.
Summary #
When using Azure Read API for processing many documents at scale (e.g., 1000’s, 10k’s or even 100k’s of documents), it makes sense to figure out a good strategy for processing them in parallel. In this post, we figured out a few highlights, so let’s summarize them:
- Use the highest available image resolution available. This will provide better recognition results, won’t cost more, and only takes slightly longer.
- Do not process files sequentially, as this does not take advantage of the parallel backend of the Read API.
- For quickest processing time, start calling the analyze API with a large mini-batch (e.g., 100 documents), then query the results using
analyzeResultsfor the mini-batch in a for-loop. This is a simple strategy, allows for easy retry-mechanism (if needed), and you avoid the hassle of dealing with multi-threading. - Leverage multiple Cognitive Services resources to get around the 10 TPS limit. Alternatively, open a support request and ask for an increased throughput limit.
With this information, you should be easily able to analyze vast amounts of documents in no time! Lastly, as Form Recognizer uses Read API under the hood, we can probably use the same strategy when recognizing forms!