Embeddings Tutorial using Azure OpenAI Service
·3 mins
Table of Contents
Introduction video #
This video post is a short introduction OpenAI’s embeddings using the Azure OpenAI Service:
Code samples #
Initial Embedding Testing #
Initialize text-embedding-ada-002 on Azure OpenAI Service using LangChain:
import os
import openai
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from openai.embeddings_utils import cosine_similarity
# Load environment variables (contains OPENAI_API_BASE and OPENAI_API_KEY)
load_dotenv()
# Configure Azure OpenAI Service API
openai.api_type = "azure"
openai.api_version = "2022-12-01"
openai.api_base = os.getenv('OPENAI_API_BASE') # looks like https://********.openai.azure.com/
openai.api_key = os.getenv("OPENAI_API_KEY")
# Initialize embedding model
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002", chunk_size=1)
Do some quick testing with embeddings:
text = "This is just a test"
# Embed a single document
e = embeddings.embed_query(text)
print(e)
print(len(e))
Try out a few more examples:
def get_similarity_from_text(text1, text2):
e1 = embeddings.embed_query(text1)
e2 = embeddings.embed_query(text2)
s = cosine_similarity(e1, e2)
print(f"Similarity between '{text1}' and '{text2}': {s}")
get_similarity_from_text("boy", "girl")
get_similarity_from_text("boy", "man")
get_similarity_from_text("boy", "woman")
get_similarity_from_text("Germany", "Berlin")
get_similarity_from_text("France", "Paris")
get_similarity_from_text("Germany", "Paris")
And with longer text:
story1 = "Once upon a time, there was a little girl named Sarah. She lived with her family in a small village near the woods. Every morning Sarah would wake up early, get dressed, and go outside to play."
story2 = "One day, while Sarah was playing in the woods, she noticed a small rabbit hopping around in the grass. She decided to follow it, hoping to see where it would go. The rabbit kept hopping until it reached the entrance of a small cave."
insurance_clause = "In the event of any losses or damages incurred by either party due to unforeseen circumstances, both parties agree to be liable for their respective liabilities and hold the other harmless for any and all damages and losses sustained."
get_similarity_from_text(story1, story2)
get_similarity_from_text(story1, insurance_clause)
Movie Description Embedding - Recommendations #
Load movie csv:
import pandas as pd
df = pd.read_csv('../data/movies/movies.csv')
# only keep original_title and overview column
df = df[['original_title', 'overview']]
# add embedding column with embedding
df['embedding'] = df['overview'].apply(lambda x: embeddings.embed_query(x))
df.head()
Calculate most similar movies (according to their description embedding):
# Let's pick a movie that exists in df, keeping in mind we only have 500 movies in it!
movie = "Frozen"
# get embedding for movie
e = df[df['original_title'] == movie]['embedding'].values[0]
# get cosine similarity between movie and all other movies and sort ascending
similarities = df['embedding'].apply(lambda x: cosine_similarity(x, e))
# combine original_title from df and similiaries and sort ascending by similarity
recommendations = pd.concat([df['original_title'], similarities], axis=1).sort_values(by='embedding', ascending=False)
recommendations.head()
City Name Embeddings Example #
Take a bunch of city names and create embeddings from them:
import pandas as pd
# generate an array with different city names
cities = ['Jakarta', 'Hong Kong', 'Tokyo', 'Bangkok', 'Shanghai', 'Ho Chi Minh City', 'Beijing',
'New York', 'Los Angeles', 'San Francisco', 'Chicago',
'Paris', 'Rome', 'Barcelona', 'Madrid', 'Amsterdam', 'Berlin']
df = pd.DataFrame({"city": cities})
# generate embeddings for all cities
df['cities_embeddings'] = [embeddings.embed_query(city) for city in cities]
Use PCA (or tSNE) to reduce the dimensionality for visualization:
# use PCA to reduce dimensionality to 3
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
t = pca.fit_transform(df['cities_embeddings'].tolist())
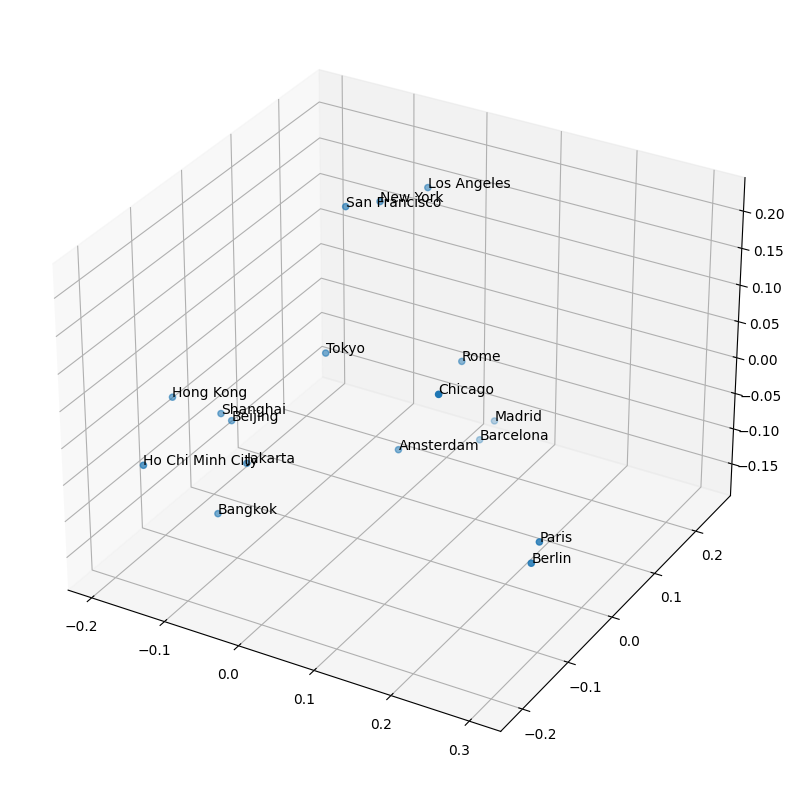
Plot to 3d scatter plot:
# draw t in a scatter plot and put names on each point
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(t[:,0], t[:,1], t[:,2])
for i, txt in enumerate(cities):
ax.text(t[i,0], t[i,1], t[i,2], txt)
plt.show()
Results: