Invoking Azure Machine Learning Pipelines from Azure Data Factory using DataPath
Table of Contents
Introduction #
This is a quick post for showing how to call Azure Machine Learning Pipelines from Azure Data Factory. This includes passing data dynamically into the Machine Learning Pipeline using DataPath.
Pipeline Creation #
First, let’s create an AzureML Pipeline that we can use for this example. Please note that this code is syntactically correct, but probably won’t run unless you adapt a few parameters, e.g., change the environment, adapt the data path, add a training script, etc.
import os
import azureml.core
from azureml.core import Workspace, Experiment, Dataset, RunConfiguration, Environment
from azureml.pipeline.core import Pipeline, PipelineData, PipelineParameter
from azureml.pipeline.steps import PythonScriptStep
from azureml.data.dataset_consumption_config import DatasetConsumptionConfig
from azureml.data.datapath import DataPath, DataPathComputeBinding
from azureml.pipeline.core import PublishedPipeline, PipelineEndpoint
# Connect to workspace
ws = Workspace.from_config()
# Get default datastore
default_datastore = ws.get_default_datastore()
# Define default DataPath for training data input and make it configurable via PipelineParameter
data_path = DataPath(datastore=default_datastore, path_on_datastore='training_data/')
datapath_parameter = PipelineParameter(name="training_data_path", default_value=data_path)
datapath_input = (datapath_parameter, DataPathComputeBinding(mode='download'))
# Configure runtime environment for our pipeline using AzureML Environment
runconfig = RunConfiguration()
runconfig.environment = Environment.get(workspace=ws, name='training-env')
train_step = PythonScriptStep(name="train-step",
source_directory="./",
script_name='train.py',
arguments=['--data-path', datapath_input],
inputs=[datapath_input],
runconfig=runconfig,
compute_target='cpu-cluster',
allow_reuse=False)
steps = [train_step]
# Create pipeline
pipeline = Pipeline(workspace=ws, steps=steps)
pipeline.validate()
# Publish pipeline to AzureML
published_pipeline = pipeline.publish('prepare-training-pipeline-datapath')
# Publish pipeline to PipelineEndpoint (optional, but recommended when using the pipeline with Azure Data Factory)
endpoint_name = 'training-pipeline-endpoint'
try:
print(f'Pipeline Endpoint with name {endpoint_name} already exists, will add pipeline to it')
pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name=endpoint_name)
pipeline_endpoint.add_default(published_pipeline)
except Exception:
print(f'Will create Pipeline Endpoint with name {endpoint_name}')
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws,
name=endpoint_name,
pipeline=published_pipeline,
description="New Training Pipeline Endpoint")
Most notably, we publish the pipeline as a PublishedPipeline and then add it to a PipelineEndpoint. A PipelineEndpoint acts as a “router” for multiple PublishedPipelines, and presents a static URL to its callers. As we re-run this code, it’ll just add our new pipeline behind the current endpoint and sets it as the new default.
Furthermore, we are using DataPath and PipelineParameter to make the data input dynamic. DataPath allows us to specify an arbitrary path on a datastore as an input, and PipelineParameter allows to dynamically pass in the DataPath when invoking the pipeline.
In the next step, we’ll call the PipelineEndpoint from Azure Data Factory.
Setup in Data Factory #
In Data Factory, first create a Linked Service to your Azure Machine Learning Workspace. Then create a new Pipeline and add the Machine Learning Execute Pipeline activity.
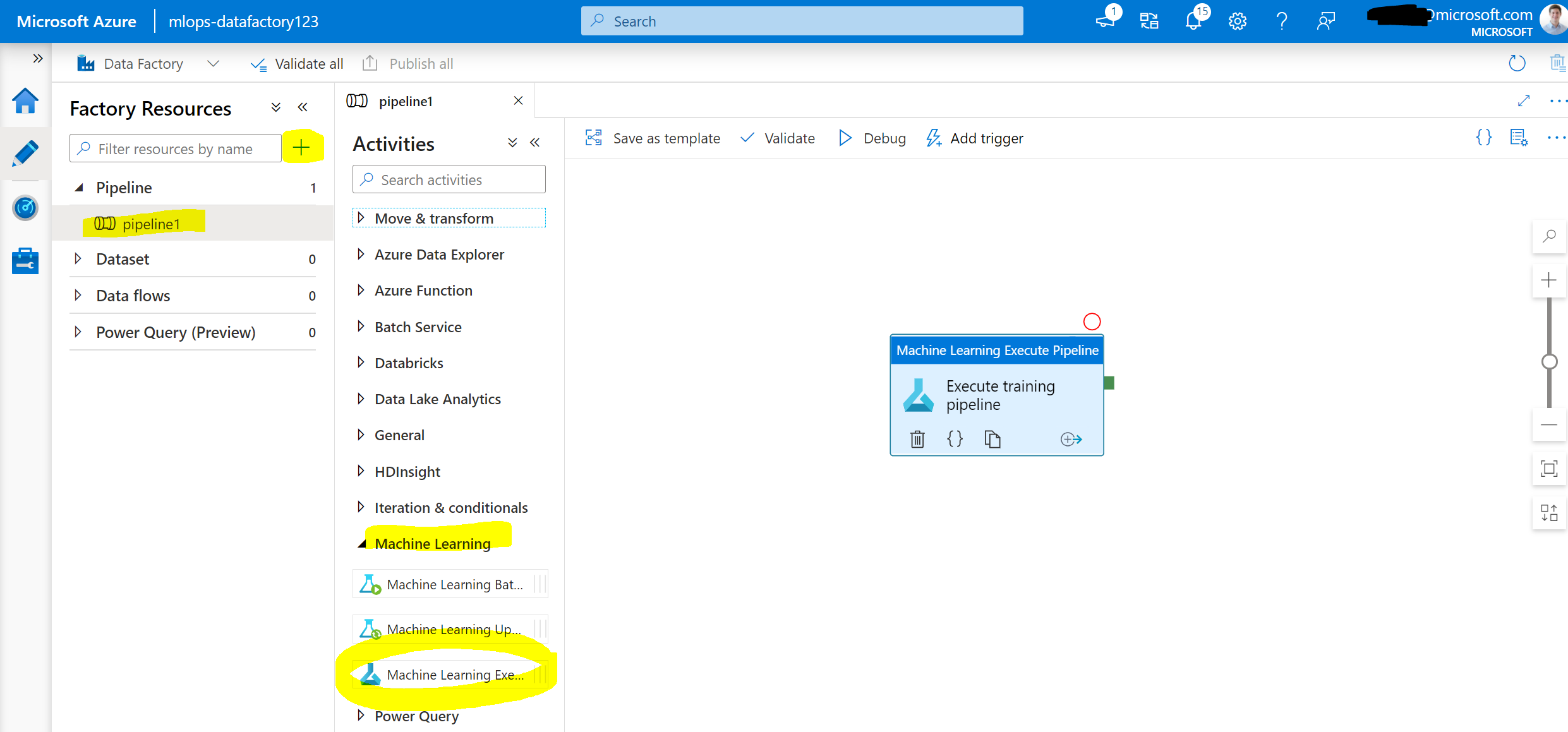
Next, we can configure the Machine Learning component:
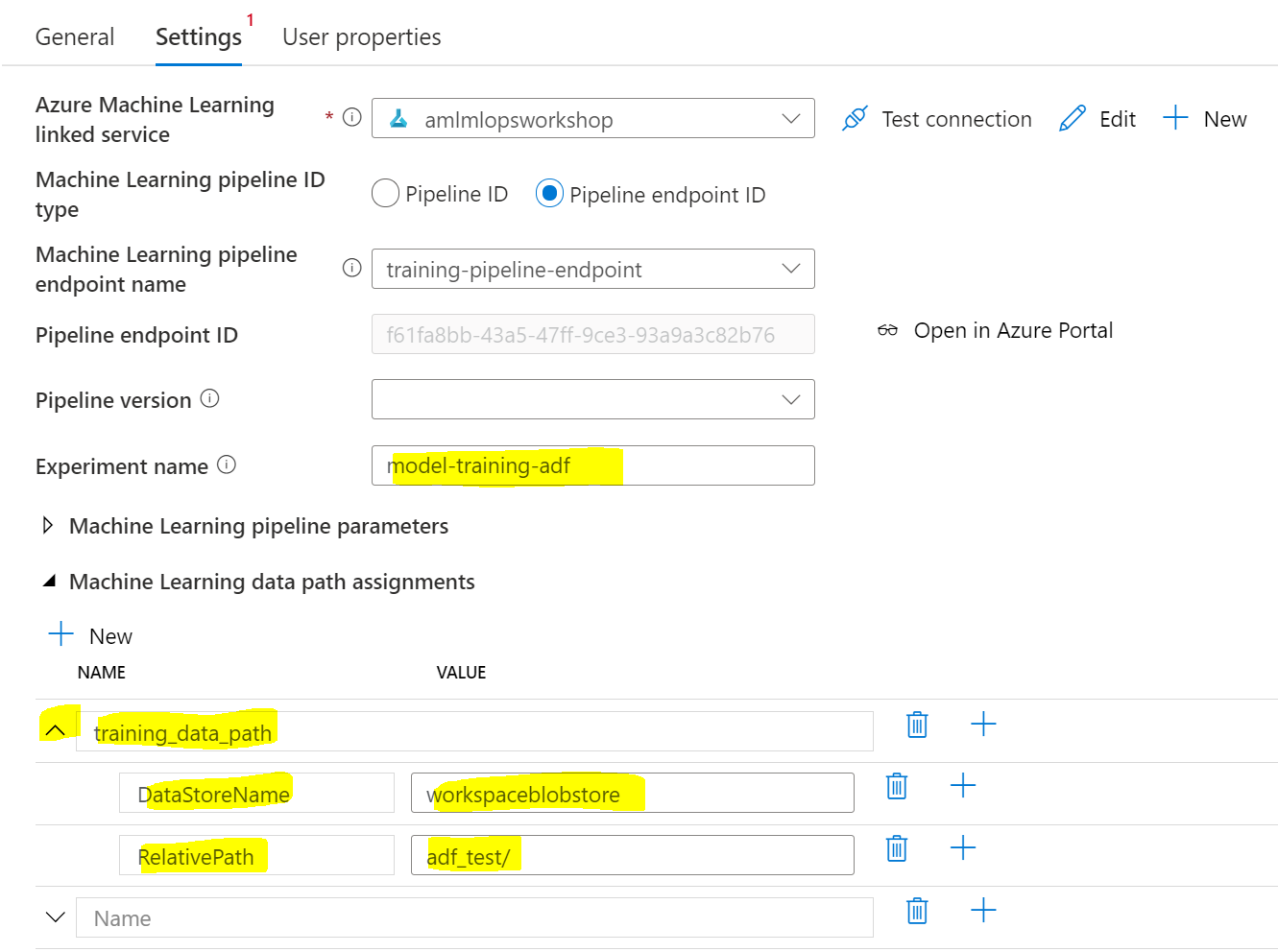
From the workspace, we can first select the pipeline we would like to execute. For this, we select our newly created PiplineEndpoint as it allows swapping out the active AzureML Pipeline in the backend – without touching Azure Data Factory. Under Experiment name, we pass in the name under which the pipeline should be executed in AzureML. Lastly, we need to pass in the DataPath via a Data path assignment. For this, we need to put the name of the pipeline parameter(s) for the DataPath in the big text box, then click the small down arrow left to it and add:
DataStoreName: point to your AzureML Datastore nameRelativePath: point to your path inside the Datastore
In this example, training_data_path was defined in our code in line 18 (datapath_parameter = PipelineParameter(name="training_data_path", default_value=data_path)).
Finally, we can publish the ADF pipeline, and run it using Add trigger, then select Trigger now. Once it ran, we should see the results in our experiment in Azure Machine Learning Studio:
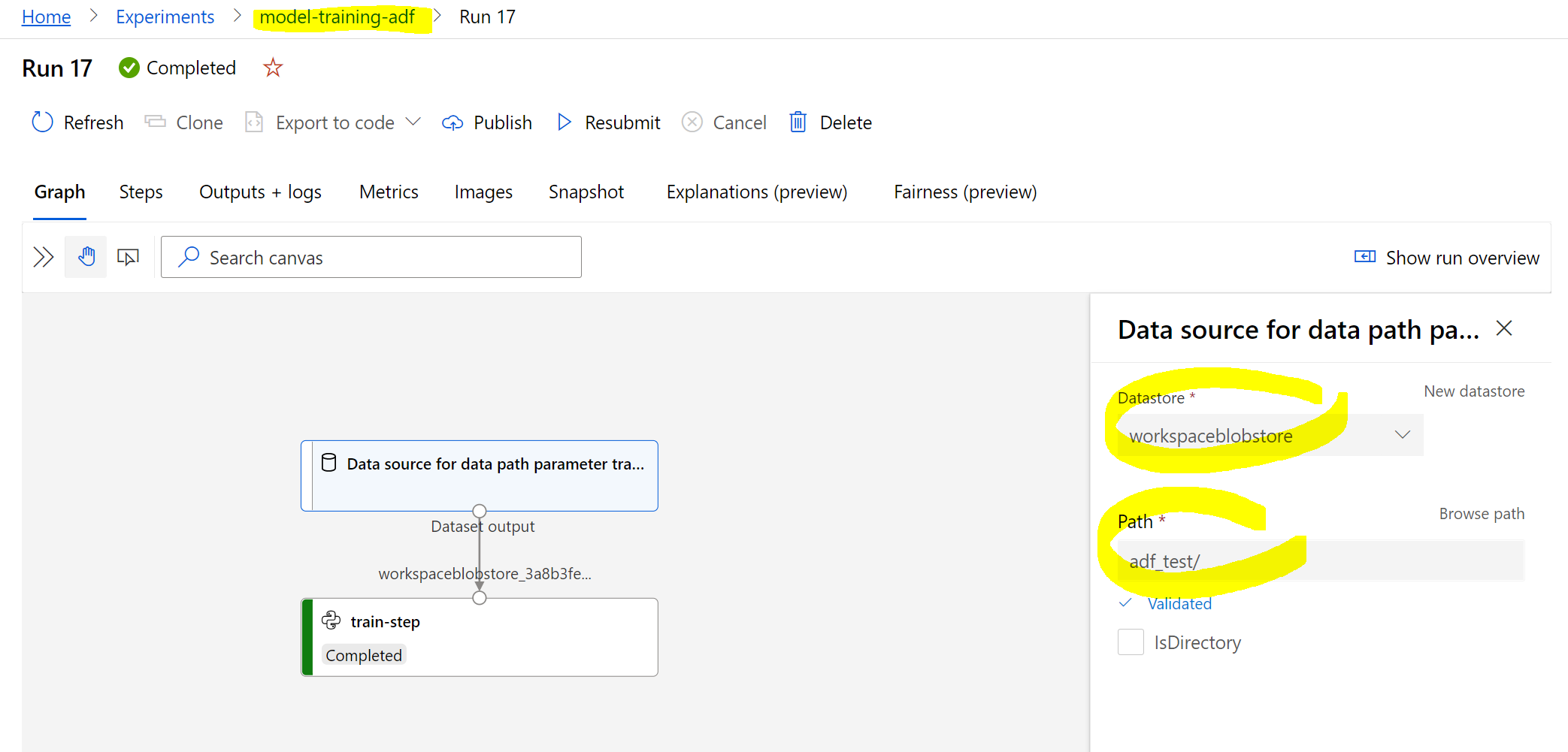
Looks good! We can see that the experiment was named properly and that the data was correctly pulled from what we set in Azure Data Factory.
Hope this quick tip was helpful!