A Guide to Azure OpenAI Service's Rate Limits and Monitoring
Table of Contents
Introduction #
In this post we’re looking into how Azure OpenAI Service performs rate limiting, as well as monitoring. For this, we’ll be looking at different scenarios for using gpt-35-turbo and discuss how usage can be optimized.
Rate Limiting Mechanisms #
There are two principal rate limiting strategies within Azure OpenAI Service which we need to understand:
- Tokens per minute (TPM)
- Requests per minute (RPM)
Let’s delve into the details of these:
- TPMs are allocated to a model deployment (like
gpt-35-turbo), defining the maximum number of tokens that can be processed per minute in an ideal scenario. TPM is measured over one-minute windows. - RPMs are derived from the TPM settings and calculated as follows:
1000 TPM = 6 RPM
When either the TPM or RPM limit is reached, the API begins to return 429 errors, indicating the rate limit has been exceeded.
{
"error":{
"code":"429",
"message":"Requests to the Creates a completion for the chat message Operation under Azure OpenAI API version 2023-05-15 have exceeded call rate limit of your current OpenAI S0 pricing tier. Please retry after 5 seconds. Please go here: https://aka.ms/oai/quotaincrease if you would like to further increase the default rate limit."
}
}
Complexities #
Upon inspecting the documentation (Understanding rate limits), we quickly realize that it’s not as simple as it might seem. For instance, the explanation of the TPM rate limit might be slightly confusing:
TPM rate limits are based on the maximum number of tokens that are estimated to be processed by a request at the time the request is received. It isn’t the same as the token count used for billing, which is computed after all processing is completed.
So, what does this imply? The TPM limit is estimated by Prompt text and count, max_tokens parameter setting, and best_of parameter setting. This is logical since the API needs to anticipate the total tokens of a request prior to execution. But as it can’t predict the completion length, it uses the max_tokens provided by the user. best_of acts as a multiplier if the user asks for additional completions. So, once the token limit based on these estimations is hit within a minute, the API starts returning 429.
Now let’s focus on RPMs:
RPM rate limits are based on the number of requests received over time. The rate limit expects that requests be evenly distributed over a one-minute period…To implement this behavior, Azure OpenAI Service evaluates the rate of incoming requests over a small period of time, typically 1 or 10 seconds.
Consider an example where we have 1000 TPMs, which equates to 6 RPM. This implies we should have one request in a 10-second window. If another request is sent within this 10-second window, a 429 error should be received.
Validation #
To validate our understanding, let’s put it to the test. I have deployed gpt-35-turbo with a limit of 1k TPM, translating to 6 RPM. I’ve chosen a low limit so that it’s easier to hit the limits (TPM or RPM) from my local machine.

Also, remember to save your ENDPOINT and KEY in a .env file:
ENDPOINT=https://xxxxx.api.cognitive.microsoft.com/
KEY=xxxxx
Requests per Minute Rate Limit Test #
We’ll use a basic script for calling the Azure OpenAI API, keeping the max_tokens at 1 and using a very short prompt (each call should cost less than 20 tokens).
import os
import requests
from dotenv import load_dotenv
max_tokens = 1
load_dotenv()
url = f"{os.getenv('ENDPOINT')}/openai/deployments/gpt-35-turbo/chat/completions?api-version=2023-05-15"
headers = {
"Content-Type": "application/json",
"api-key": os.getenv("KEY")
}
for i in range(1000):
data = {"max_tokens": max_tokens, "messages":[{"role": "system", "content": ""},{"role": "user", "content": "Hi"}]}
try:
response = requests.post(url, headers=headers, json=data)
status = response.status_code
if (status != 200):
print(response.json())
print(f"Finished call with status: {status}")
except Exception as e:
print(f"Call failed with exception: {e}")
The log output should display:
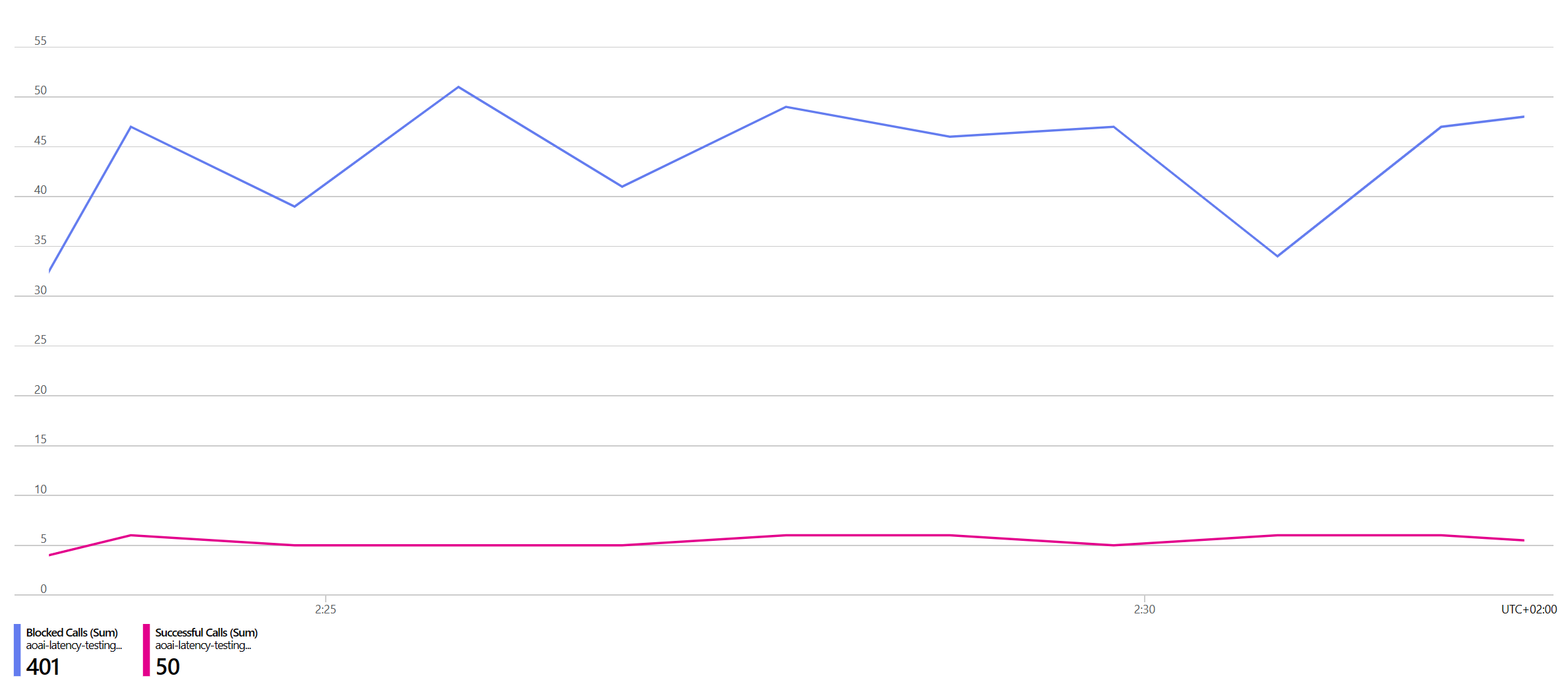
- An API call is processed approximately every 10 seconds
- Roughly 6 calls are successfully completed per minute (this could be 5, depending on the exact timing)
The resource’s monitoring tab in the Azure Portal confirms this behavior (“Successful calls” and “Blocked calls”):
Tokens per Minute Rate Limit Test #
Let’s repeat the process, this time aiming to breach the TPM limit. We simply change max_tokens to 1000.
max_tokens = 1000
The log output will show:
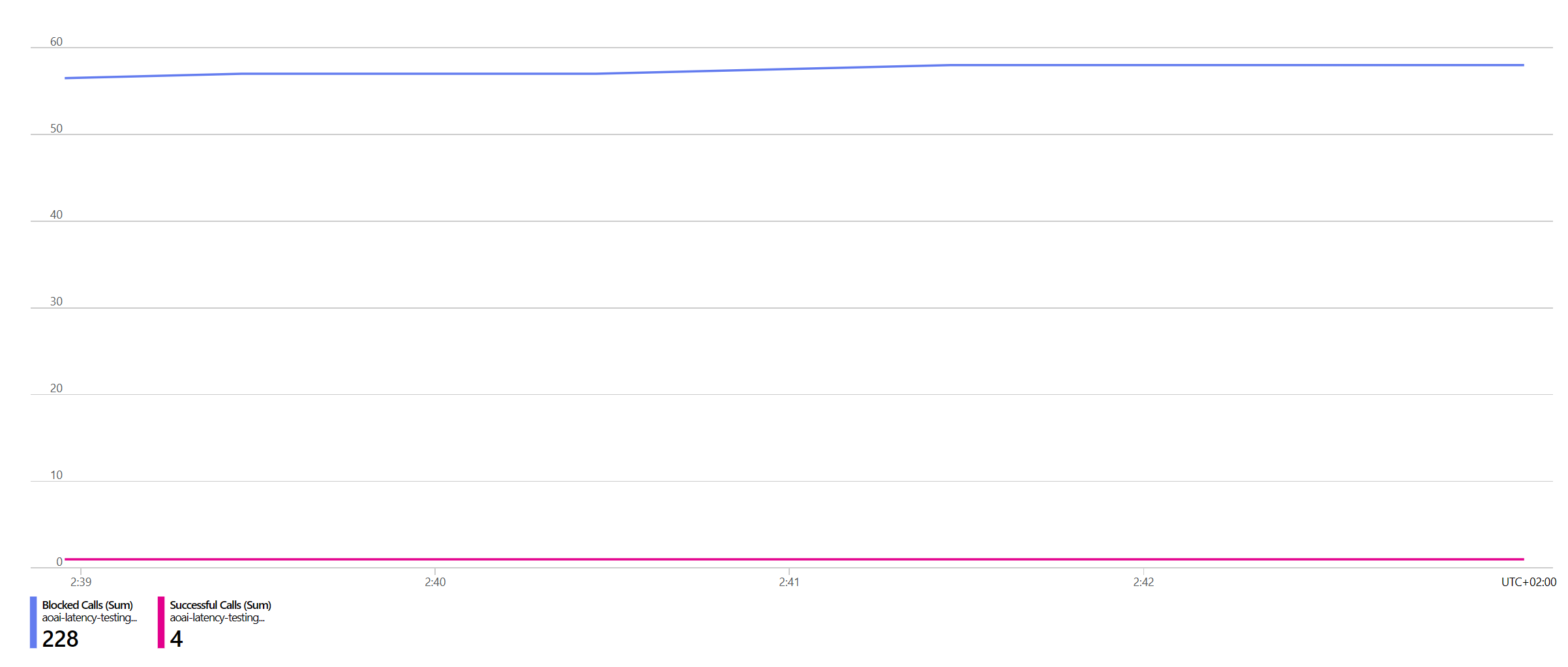
- Only one API call will be processed per minute
- All other calls will result in
429errors
The monitoring tab validates this:
Thus, everything operates as anticipated!
Key Takeaways #
Now that we understand how the rate limiting works in detail, what can we learn from it:
- Maintain the
max_tokensparameter at the smallest feasible value while ensuring it is large enough for your requirements. - Increase the quota assigned to your model or distribute the load across multiple subscriptions or regions to optimize performance (also refer to Optimizing latency for Azure OpenAI Service). Consider fallback options such as
turbo-16korgpt-4-32kwhen reaching the quota limits ofturboorgpt-4-8k. These alternatives have independent quota buckets within the Azure OpenAI Service. - Implement retry logic into your code. This strategy is particularly beneficial when you encounter request rate limits, as these limits reset after each 10-second window. Depending on your quota, the reset time might be even faster.
If you need practical advise on how to implemented the recommendation outlined here in LangChain, have a look at this post: Using LangChain with Azure OpenAI to implement load balancing via fallbacks.
Happy “rate-limit-avoiding”!